
第14回の「Modern Data Stack特集」では、様々な最新の技術スタックが紹介されました。
今回の勉強会では、その中の1つである「Reverse ETL(リバース イーティーエル)」について深掘りして学んでいきます。
Reverse ETLは統合・蓄積したデータをビジネスに活用する重要な技術要素です。実際にReverse ETLを業務の中で活用されている企業のご担当者をお呼びし、レコメンド・メール配信など複数のユースケースをお話しいただきます。
第15回は「Reverse ETL特集回」と題して、3名の方々から実際のビジネスにおいてデータ基盤・データの活用をより進めていくためにはどのような工夫が必要なのかを学んでいきます。
1つ目の講演はClassi株式会社の方をお呼びし、社内データ基盤だったものをプロダクトに開発した話を、そして2つ目の講演では株式会社ZOZOの方をお呼びし、メール配信のアーキテクチャと直面した課題の解決策をお話ししていただきました。
そして、3つ目の講演では株式会社アドウェイズの方をお呼びし、更なるデータ活用をするために行ったことを具体例を交えてお話いただきました。
当日の発表内容はこちらになります。
講演「ReverseETLでユーザーに価値を届ける基盤を実現した話」
出典:St-Hakky、「ReverseETLでユーザーに価値を届ける基盤を実現した話」、https://speakerdeck.comより
齋藤 和正 氏
社内の基盤として運用していたデータ基盤をベースに、その集計結果をReverseETLしてサービスに組み込んだ話を紹介します。AWSとGoogle Cloudのクラウド間を行き来するデータパイプラインの実現のために必要であった、監視や運用面の改善などについても触れながら紹介します。また、本取り組みにより見えてきたデータ基盤の在り方から、現在目指している基盤についても紹介します。
Classi株式会社 データ基盤チームリード
twitterのアカウント
元々社内のデータ基盤だったものをClassiのサービスの一部としてReverse ETLを行い、提供するまでに至った経緯やアーキテクチャについてお話ししていただきました。
Classiとは

齋藤 和正氏:「ClassiはBenesseとSoftBankのジョイントベンチャーで2014年に設立し、教育プラットフォームとして会社名と同じ「Classi」の開発・運営する会社です。
学校法人に対して、教育におけるICT活用を推進していくプロットフォームを提供しています。例えば、コミュニケーション機能やwebテストの配信などをできる機能があります。現在のサービスの提供状況としては高校生の3人に1人が利用しているサービスです。
Classiのデータ基盤の取り組みとして、会社のビジョンとして「データテクノロジーを活用し、先生たちと一緒に成長の仕組みと場面を提供していきたい」があるように、サービスの価値を高めていく取り組みを行っています。」
詳細なClassiのデータ基盤への取り組み

齋藤 和正氏:「Classiは業界の中でも、早い段階からデータ基盤への取り組みをチームで行なっています。気になる方はブログやスライドを確認してください。」
ブログのリンクはこちら・「Classiのデータ組織の歩み」のリンクはこちら
ReverseETL実装の経緯について

齋藤 和正氏:「最初からETLを導入しようとしたというよりも、「結果的にそう呼ばれているものになった」という方が正しく、そこに至るまで次の3つの経緯がありました。
一番大きかったのは、ダッシュボード機能のリリースです。これは2022年の春にリリースしましたが、Classiのサービスの一つとして「ダッシュボード機能」という生徒の学習状況などを把握するための機能をリリースしたいという背景がありました。
そこで、社内の一番大きい基盤である「ソクラテス」を活用し、集計を実装した方が機能要件的にも実装コスト的にも適切だと考えました。また社内基盤とはいえ、安定性の向上に関しては長い間取り組んでいたので、「カント」と呼ばれるデータ基盤の状況把握を行うための基盤を活用する形をとりました。それによって、品質が向上やSLO/SLAを定義して運用改善していくことが可能になったので、プロダクトとして提供しても問題ないと判断しました。」
詳細:データ分析基盤:「ソクラテスとは」

齋藤 和正氏:「ClaasiはAWS上で構築されており、Google AnalyticsやSalesforceなどのデータを統合的に管理するデータ分析基盤をGoogle Cloud上に構築しています。いわゆる、マルチクラウドなデータ分析基盤になっており、Tableauやredashを使ってデータを見る形になっています。」
ダッシュボード機能について

齋藤 和正氏:「ダッシュボード機能は、生徒の学習状況を可視化したダッシュボードを提供する機能で、ざっくり言うと、利用上をデータとして集計して、Summaryの情報を機能として提供するものです。
アプリケーションはAWS上で動かすことになっており、ダッシュボードもAWS上で動かすことや、前日までの利用上が朝8時までに閲覧可能になっていることがシステム的な要件として提案されました。」
データ分析基盤「カント」

齋藤 和正氏:「カントはClassiのデータ基盤のジョブの実行状態を把握することができる基盤のことです。機能としては、「ヘイゲル」「ソクラテス」などのデータ基盤のコンポーネントごとにSLO/SLAを設定して、いつまでのどのジョブが終わっていないといけないかを計測したり、監視したりできる基盤になっています。また実行状態・実行時間も見ることができ、エラーを見ながら優先度を確認できる基盤です。」
reverseETL実装の経緯まとめ

齋藤 和正氏:「①社内データ分析基盤である「ソクラテス」や②データ基盤の安定性向上のための監視基盤としての「カント」があり、③プロダクトとして実際に提供するという3つの背景に加えて、社内のデータ基盤の利便性及び品質向上の取り組みによって、ユーザー提供に十分な基盤になりました。また、データを集計することは「ソクラテス」が一部担っていたので、開発のリソースを考慮し、逆にAWSに書き戻すアーキテクチャにしようという意思決定が行われました。」
ここからは実際に、Reverse ETLのアーキテクチャをどのように書き戻したのかをお話ししていただきました。
アーキテクチャのForwardとReverseについて

齋藤 和正氏:「アーキテクチャの全体像としては下側がForwardで、通常のデータ基盤の構築の流れになっており、上側がReverseで、書き戻しにいくところになります。」
Forwardのアーキテクチャ

齋藤 和正氏:「ForwardはAWSでプロダクトを構成しています。Glueを使ってデータ連携をし、S3上に一度データを連携して、そこからCloud Composerを使ってデータマートを作っていく流れになっています。
プロジェクトの工程の分かれ方はGoogle Cloud上で、DataLake用プロジェクトとBIツールを使ってデータを覗くDWH/DM用プロジェクトに分かれています。
一見すると、よくあるアーキテクチャのようですが、青枠で囲ってある部分が監査と呼ばれる部分になっていて、Lambdaを使ってGlue・AWS側のジョブの状態を取得してGoogle Cloud上に流し込んだり、CloudComposerのタスクの状態も同様に流し組む形になっています。また、Cloud Loggingの方に一度流して、Log Routerを伝ってBigQeuryから閲覧が可能になります。
この仕組みだと、実装コストがあまりかからず、Lambdaを使ってAWSとGoogle Cloudを跨ぐジョブの実行状態の管理・把握ができるようになりました。」
Reverseのアーキテクチャ

齋藤 和正氏:「書き戻す処理は、集計対象のデータをDataLake用プロジェクトの方から取ってきて、ダッシュボード機能用のプロジェクトの方でCloud Composerを使って集計します。そして、集計が終わったらStep Funstionを叩いて、lambdaを経由しRDS側に書き戻しています。」
アーキテクチャの構造はシンプルですが、元々社内基盤だったところもあり、ユーザー影響のあるプロダクションとして使われる基盤になったので、そこを踏まえて意識して変えたところをお話ししていただきました。
プロダクションのために4つの変更

齋藤 和正氏:「1つ目は「社内用の処理とユーザー影響のある処理の分離」です。Google CLoudのリソースの観点では、元々dataLakeとDWHとデータマートに分けていたので、問題はありませんでした。しかし、CloudComposer上でDAGの処理が混ざってたので、そこを分離しました。社内版メリットである利便性は落としたくなかったので、社内用は気軽にデプロイできるようして、プロダクションは固く作るように処理の分離を行いました。
2つ目は「データ基盤のSLO計測」です。実際にプロダクションとして提供していくために、朝8時までにデータを届けることができるのか、どこがボトルネックになりそうか、処理が出来なさそうになっていないか、などを見れるように「カント」プロジェクトで毎回改善サイクルをチームで回しています。
3つ目は「alert基準と通知の見直し」です。社内基盤の方では、後続の処理でalertが飛べばいいようにして、alertを仕込めていない部分もあったように、十分に対応できていませんでした。そこで、Error以外にも処理が遅れている時に気がつくために遅延通知を導入しました。
4つ目は「デプロイフローの変化」です。データ基盤においてデータの依存性が生じることがあります。devからプロダクションに同じような環境をあげたり、CIでのチェックを強化したりすることで、プロダクションの方にあげれるようなレベルになりました。同時に社内におけるデータ基盤の改善され、社内で使う際も安定性の向上も見られました。」
さらに、こういった取り組みを行なっていた時に考えていたことをお話いただきました。
齋藤 和正氏:「通常プロダクト開発などで、バックエンド・フロントエンドを開発する時に普通にやるDevOpsを、データ基盤で着実に実現することを意識しました。
「社内基盤だから」・「データに依存するから」といった理由で怠りがちな環境の分離や関心の分離、SLOの計測・監視・アラート設計といった、元々整えていた部分をより強化してユーザーに価値を与える基盤へと変化させることできました。
特に、Classiのデータエンジニアチームでは、データ基盤のチーム開発を2年ほどやっており、障害発生時のポストモーテムの実践や開発スプリントの実践をプロダクト開発と同じように行ってきました。「分析に止まらないデータ価値提供」を意識して、システム間連携におけるサービスレベルの担保に求めれることは通常のプロダクト開発と変わらず行ってきました。」
最後に、今後に向けてチャレンジしたいことをお話ししていただきました。
齋藤 和正氏:「2022年2月に、データAI部内のミーティングで、Modern Data Stackや前回のDESで取り上げたトレンドの部分、ReverseETLに限らずデータの価値を高めていけるデータ基盤を目指して、どういった取り組みをしていくかを発表しました。
ReverseETLのようなデータを書き戻すといったものであったり、Modern Data Stackといったトレンドの、個人的解釈になるが、データ基盤の社内ユースケースはもちろんだが、プロダクトして今回提供するコストが下がってきています。
まだまだ大変なところもありますが、「データで価値を提供するのが楽になってきている」中で、「データの価値提供の方法を捉え直す」必要が出てきました。今まではコストの関係でできなかったり、技術的に難しかったところが変わってきていると考えています。」
ReverseETLは価値提供の手段の1つに過ぎない

齋藤 和正氏:「通常の考え方とは逆説的になりますが、各プレイヤーがどういった領域でどのようなサービスを提供して、どういった価値を提供しようとしているかを考えたり、今あるデータ基盤をより価値あるものに変えるとか、ユーザーに価値提供を行えるようにできるのでないかというところで、サービスを抜いた形でデータ基盤の構成要素を捉え直しています。それによって、それぞれの部分で今自分たちが注力するところ・一番メリットが出せるところはどこかの議論につながります。
最近だと、より安定性を求めてメンテナンスしやすい基盤構築であったり、アジャイルに機械学習の開発を行いたいとか、セキュリティとデータ分析基盤の利便性のバランスを整えたりすることに力を入れて開発をしています。」
講演「データをコネコネ!メール配信用データ生成の仕組み」
出典:kappezoro(辻岡温子)、「データをコネコネ!メール配信用データ生成の仕組み」、https://speakerdeck.comより
辻岡 温子 氏
各種メールマガジン配信用データの生成や連携処理の仕組みについて紹介します。運用時に対面した課題の解決方法や、工夫点も併せてお話しします。
株式会社ZOZO MA部MA施策・運用改善ブロック
twitterのアカウント
まず、初めに今回の講演はどのような方におすすめかをお話いただきました。
・連携先SaaS都合でデータ抽出後ファイルを分割作成&並列処理したい
・DBのデータ量×長クエリで実行遅いのなんとかしたい
・クエリコピペ量産してて運用しづらいのなんとかしたい
ZOZOのマーケティングオートメーション(MA)における配信システムの種類と流れ
辻岡 温子氏:「システムの種類は、MAのメールのデータ抽出は主に、2種類の配信システムで行われています。マス配信は例で言うと、ZOZOGLASSの販売開始などの一定セグメントに対して、一斉に対象者に対してメールを起こすシステムです。
2つ目のパーソナライズ配信は、最適化によって特定条件を満たす対象者に対して配信をするシステムです。例えば、お気に入り登録したユーザーがその商品が値下げした時に、その情報をリアルタイムに取得して、ユーザーごとの適切な配信時間やプッシュ通知などのチャネルを最適化して配信するシステムです。」
メール配信全体の流れ

辻岡 温子氏:「真ん中のcreate datamart/data transferを境に上がマス配信で、下がパーソナライズ配信です。商品やユーザー情報などの基幹データを左上のSQLサーバーに保管しています。マス配信の場合はBigQueryを、パーソナライズ配信はReplicaitionDBによってリアルタイムにデータを取得しています。これらの基幹データや機械学習を用いたrecommendmodelsもBigQuery上に置いて、配信情報を作っています。
マス配信はBigQuery上にDigDag経由で配信データを出力して、SaaS用にCSVファイルを生成し、それをSaaSに送って配信します。パーソナライズ配信はPostgreSQLとReplicaitionDBからDigDag経由で配信データを抽出してCSVファイルを生成し、SaaSに送って配信する形になっています。」
3つに分割してアーキテクチャを見ていく

辻岡 温子氏:「今回トピックとして挙げるのは、この赤枠で囲った3つのデータ連携です。後ろから番号を振って説明しているのは、課題が見えたりその前の工程でそれを解決する背景が見えるためです。
1つ目がSaaSとの連携部分、2つ目がBigQueryとPostgreとの連携部分、3つ目がBigQueryからBigQueryになっています。」
Data mail file for Massとcreate mail file for Personalizeについて細かく見ていきます。
①メール配信のファイル作成の構造

辻岡 温子氏:「マス配信はBigQuery経由で、パーソナライズ配信はPostgre SQLとSQL Serverを使って、DigDagを基盤とした処理でcsvを作成し、SaaSに連携して行きます。 パーソナライズ配信ではDigdagでjavaのアプリケーションを動かしてS3に一回csvを出力し、それをSaaSに連携して行きます。ただSaaSには様々な制約があり、ファイルサイズの制限があります。それを超えると送信できなくなるので、ファイルを分割することをパーソナライズ配信ではやっています。
一度の配信量はユーザーフックで送るので、一度の配信量はマスに比べると、そこまで多くない分、パーソナライズではSaaSの連携については課題はあまりないと言えます。」
マス配信における問題点

辻岡 温子氏:「マス配信はサービスの制約でも課題がありました。まず一度に大量に配信をしないといけないので、配信ボリュームが多く、その影響で1つの配信に対して、SaaSにファイルサイズの規定を余裕で超過します。ファイルの分割は可能ですが、ファイルが規定に収まるサイズで切って直列配信すれば、一気に送りたいものが少しずつ送られる形になるので、SLAを余裕で超えます。
ファイル分割した上で並列実行して一気に送りたいが、MAのメルマガ配信でメルマガ配信は24時間365日送っているところは基本的はありません。配信時のみスケーリングやリソース調整して素早く動かしたいとなったので、Digdag On GKEを導入しました。」
Digdag on GKE Autopilotとは
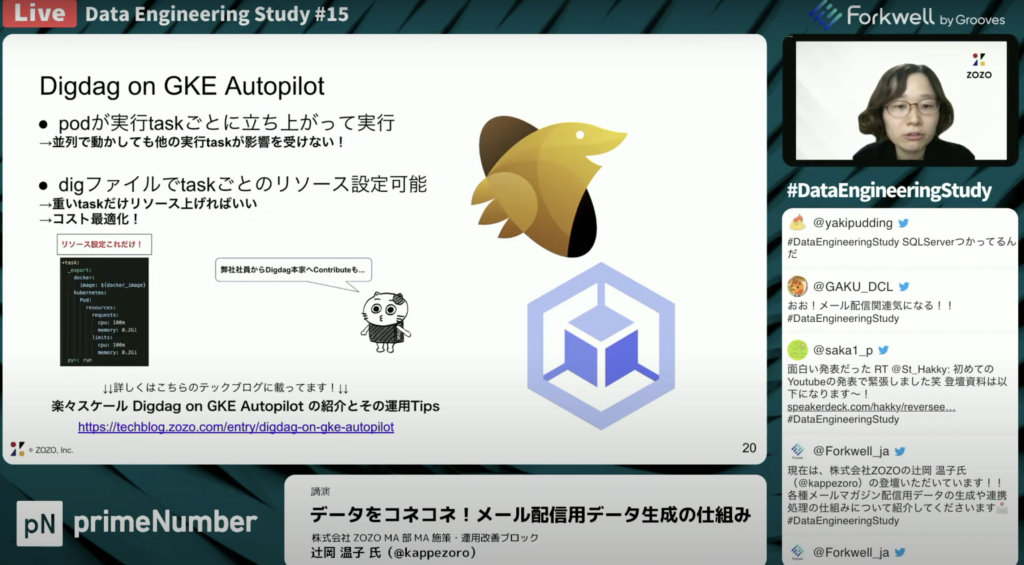
辻岡 温子氏:「Google Kubernetes Engine(GKE)上で動くDigDagの基盤です。利用側にとってメリットが大きく2つあります。1つはpodが実行タスクごとに立ち上がって実行できる点です。どれだけ並列で動かしても、単一インスタンスで並列処理を行ってリソースを食い合うことはなく、Digdagのほかの実行タスクが影響を受けないというメリットもあります。
並列実行はDigdagファイルでパラレルというオプションをつけるだけで簡単にできます。 Digファイルタスクごとのレポートのリソース設定が可能です。大概のリソース設定でインフラ用の設定ファイルがデフォルトで、指定したものから変えられないことがあると思いますが、Digファイルに設定を書くだけでリソース設定ができるっていうメリットがあります 。
これによってマスメールの課題であった並列実行は、podごとに独立して増やすことができ、ファイルを生成する際にリソースを使うのでそのタスクだけpodのリソースをマッピングで増やして最適化を実現できました 。」
Create datamart/data transferを行うPostgre SQLとBigQueryについて見ていきます。
②配信用データ作成の構造

辻岡 温子氏:「BigQueryのデータは一度Postgre SQLにデータを渡し、パーソナライズ配信はPostgre SQLとSQL Serverのデータを使ってcsv出力して配信する仕組みになってます。SQL Serverは商品やユーザー情報等が入っていますが、Postgre SQLにはそれ以外のパーソナライズしたデータが入っています。BigQueryなどの基幹データ以外の連携するデータや実績のデータであったり、この箇所の手前でアプリケーションが別で動きますが、対象者を最適化して抽出する処理がのデータがここに入っています。」
ここでも問題が生じるについてお話していただきました。
BigQueryでSLA超過を解消

辻岡 温子氏:「Postgre SQLに複雑なクエリと非常に大量データが相まって、いくらチューニングしてもSLAを超過するクエリが出てきてしまいました。そこで登場するのがBigQueryです。
大量データで複雑クエリではBigQueryが一般的で、適材適所にするようなやり方をして解決しました。SLAを超過したときは実績データやレコメンドモデルのデータ等をPosgreに持って来てから、Postgre SQLでクエリ実行していましたが問題が発生しました。
そこで、Digdagとembalkを利用してPosgreから一回BigQueryに該当のクエリで使うデータを渡して、クエリの実行はBigQuery任せるようにしました。 その結果をDigdagとembalk使って、Posgreに戻すようにしました。設定はLiquidと呼ばれるテンプレートエンジン用のファイルにYAML形式で接続情報や実行クエリを書くだけで簡単にデータの受け渡しができるので、簡単に連携ができました。」
③BigQueryからBigQueryのデータ転送の構造

辻岡 温子氏:「メールの抽出クエリは非常に歴史が長く、10年以上どんどん続いてビジネスロジックが積み上がって運用されてきました。結果として、複雑だったり類似クエリだったりもありながらも、さまざまなクエリが実績を残していっています。
これらが冗長になって起きた課題としては、全体の変更が発したメールで全体的に変更がしたい時に、調査・改修・テストのコストが上がっていった点ととビジネスロジックの可読性そのものが下がってきたことが課題になりました。 そこで解決する策としてクエリをリファクタリング(部品化)する選択をしました。」
SQLを「部品化」する

辻岡 温子氏:「なんか似ているけど、ところどころ違うクエリが散見されることがよくあると思います。そのような似てるけど所々違うクエリを細かく分割して、クエリ単位でファイルを分けて共通利用できる箇所は、同一ファイルを使ってクエリを実行するようにしました 。
左のSQL_AとSQL_Bの二つが部品化前のクエリで、右側のa,bは部品を作った後にoriginal_a、 original_bのように、それぞれの部品を参照するようにして部品化によるリファクターを実現しました。 」
最後に部品化のメリットお話ししていただきました。
「部品化」のメリットはたくさんある
辻岡 温子氏:「リファクタリングのメリットは中間データの参照がしやすくなったり、データ不備の調査がしやすくなったり、ビジネスロジックの可読性が上がる等のメリットがあります。BigQueryで発生する「too complex」というエラーを部品化することで解消につながってます。 また、共通ロジックの変更や一斉変更が発生する際には、改修コストが一気に下がるというメリットがあります。
ただ、クエリを作っても継続的に使えるかわからない場合もあるので、結果出るまでは借金してもいいかなと思います。急ぐ必要があるかっていうのは状況次第かと思いますが、やっておくとこういったメリットがあるんだよっていうところをご理解いただければと思います。」
講演「SFA/CRMの構築を通じたデータアクティベーションと組織開発」
出典:中越健太、「SFA/CRMの構築を通じたデータアクティベーションと組織開発」、https://speakerdeck.comより
中越 健太 氏
レポート・ダッシュボードで「見る」で終わらないデータ活用には、何が必要か?
株式会社アドウェイズ プロダクトDiv
Professional Platform Producer
troccoを活用して、Big QueryとSalesforceの双方向のデータ集積と転送を基盤とすることで、生まれた営業組織の変化とこれから。
「作る」「見る」為のデータ収集・蓄積から、ビジネスサイドの現場から取り組んだ”データアクティベーションと組織開発”で成果が見えるまでの取り組みの事例を共有します!
twitterのアカウント
まずはじめに、中越氏が所属されている会社について紹介していただきました。
株式会社アドウェイズについて

中越 健太氏:「株式会社アドウェイズはインターネットの広告代理店として、いくつかの事業を展開しています。AMPというシリーズで広告の方データ活用というところで、広告運用のシステムという形でいくつかシリーズ化など、様々なプロダクトを展開しています。」
Reverse ETLではなく、Data Activationを扱う理由

中越 健太氏:「前回の14回の発表の際に ReverseETLでデータの複製を想起させてしまうよねっていうのは、名称のところからあのデータを使って意思決定のためのデータ分析だけでなく、アクションをとることにフォーカスすることとしてみれば、リブランディングの話したところが最後のほうにあるので、それに付随するような内容を話します。」
見るで終わらないデータ活用へ ”データアクティベーション”と”組織開発”

中越 健太氏:「大枠のイメージとしては、目標や商談等の点在したデータをDWHに返してBIやSFA/CRMにデータを流すという感じです。主に左側のデータアクティベーションという領域と右側の組織開発つまり、いかにしてその課題に適応させていくのかについてお話をさせていただければと思います。データは集まり、機能はできたけど、現場で活用に至らないといった壁を少し乗り越えるに至るまでのお話が本日のテーマになっています。」
アドウェイズがどのようなところからスタートしたのかをお話ししていただきました。
アドウェイズのスタート地点

中越 健太氏:「ワークフローやレポーティングのためにデータは溜まっていたところからのスタートでした。左側にあるデータはBigQueryにデータが溜まっていて、主にはお客様向けのレポートや広告運用システムで使われていた状態でした。
ただ、事業の中で先行指標となるようなデータの計測や連携の進みが悪く、スプレッドシートで運営されているいうのがこれまでの状態でした。なので、顧客向けのレポーティングや配信の最適化のためにデータは溜まっていたところから、自社の営業とか事業活動に向けてデータをアクティベーションして行くと言うところが最初のスタートラインでした。」
データ投入開始時の壁

中越 健太氏:「構想策定・SFA/CRMを構築してデータを流し込んでいくことを考えました。当社ではkintoneや広告配信のデータはBigQueryに溜まり、人事や目標の管理のデータはSalesfroceに溜まっている状態からスタートしました。それらをtroccoを返してデータの運輸を行い、Salesforceの方に投入して計画と活動を促します。
BigQueryのプロジェクトの分散や理想の実現のために、データが分散している状況でしたが、troccoのグループ機能を活用してBigQueryのプロジェクトも1つに集約しながら、グループ機能で可視化を行い、オープンにDWHやとDatamartの定義を進めました。」
ここからは具体的なお話もしていただきました。
ツールの集約における選定方法

中越 健太氏:「1つはツール選定です。DWHはこれまでにAWSやBigQueryなどで分散をBigQueryに集約しています。ETL/ELTの領域に関しては、Asteria warpやCDataなどのコネクタを使っていましたが、今回のプロジェクトにおいてはtroccoに集約しています。SFA/CRMの領域に関してはkintoneやスプレッドシートでかなり分散していたところをSalesforceで集約しました。
こういった中で、どうツールを選定していくかについてですが、「安い。シンプル。わかりやすい。」ではなくて、いかにして事業・プロダクトのビジョン達成の為に、どのようなデータプロセスが最適化かを考えました。とりわけ、技術だけでは課題解決ができないとこういうところがすごく実感としてあったので、こういったところを重視しました。
その中でも、「オープンなのか・リレーションが容易なのか・コラボレーションが生みやすいのか」の3点が、 ツールの選定基準の中にありました。」
さらに踏み込んだ内容をお話いただきました。
データフローの概要図

中越 健太氏:「マスタと受発注のkintone側のデータに関しては、troccoを介してETLでBigQueryの方で一度集約し、運用広告の管理画面等からとってきたデータに関しては、Asteria warpを用いて成形してBigQueryに蓄積します。運営する広告に関してはBigQueryの方に蓄積されているログを利用してSQLで加工したものをBigQueryに蓄積をして 、Salesforceに関してはtroccoを介してETLでBigQueryへ蓄積します。
階層をしっかり作ることで見るところと、活用のところを適切な単位でデータを開けて蓄積していく形になっています。」
次に、蓄積したデータをどうアウトプットして行ったのかをお話ししていただきました。
データ更新・記録の運用サイクル

中越 健太氏:「Salesforceの運用のサイクルは、月曜日から水曜日にかけてメンバーユニットのマネージャーが、バトンを渡すような形で案件単位の数値の報告・個人別の数値・ディビジョン単位の数値の報告を取得したデータに対して、要因等を付け加えてバトンパスして行く形になっています。
最終的にはSalesforceのダッシュボードで全員が見れるという形になっています。」
ユーザーが使いやすいレイアウトに

中越 健太氏:「左側は様々なところから収集してきたデータをアウトプットする形になっていて、Salesforceでは主には右側で記録を行う形を各オブジェクトごとにレイアウトを意識して作っています。利用者側としては、各オブジェクトごとに左側でデータを見て右側の方で入力するというところを徹底して構成されています。
データ活用の仕掛けとして、左側で連携・集計されたデータを見て、右側で計画や行動を記憶する基本構造としてレイアウトを設計しました。」
取り組みの中で期待していた2つのアクション

中越 健太氏:「1つ目は、営業活動の記録がスプレッドシート等の手元に記録されている状態だったので、Salesforceに記録してもらうことです。2つ目の期待は、当月の数値の予測をSalesforceの方で各部署を標準化・共通化させることです。ただ、活動の記録に関して中々定着せず、ロジックを組んで数字の予測をしても、数値が一致しないという壁にぶつかりました。
技術的には上手くいきましたが、やっていく人間がどう活用するのかわからないから、“やらされてる”形になってしまったのが最初にぶつかった壁でした。データ活用を自分ごと化すべく、可視化・資産化・逆算型の言語化していくことになりました。」
2つのギャップの解消

中越 健太氏:「直近では理想と現実、計画と行動に対してのギャップを明らかにして、アクションを計測するところに大きく取り組んできました。1つ目は、上場企業で課されている目標に対して、計画・数値予測のギャップを明らかにしました。
もう1つが広告側の営業と媒体側の営業など、部署の中で追っていくべきKGI・プロセスKPI・アクションするべきKPIのギャップを明らかにした上で、その活動をそれに紐づけていくところを営業側と対話をしながら、指標を設計し、Salesforceに記録していくことを始めました。
2つの視点で課題やギャップを可視化して、アクションプランの計画記録することで、単純にデータを入力してもらうところから、自分たちがどういう風にして行きたいのかを強く引き出していると考えています。」
最後に、本日のお話をまとめていただきました。
作る側と使う側の好循環を目指して

中越 健太氏:「データは元々、レポーティングのために蓄積されていたというところからスタートして、データ活用の構想策定・データ集約して、入力できるようにして計測ができるようになりました。やらされている感が否めないと言うところから、理想の言語化やギャップに対しての計画・行動を一緒に記憶して行くことを推進してきました。
また、自分たちのようなデータを作る側がしっかり理想を提示した上で、適切な指標を設計し、検証・改修をしていくところと、データを使う側の方でもそれらを鵜呑みせずに、改めて提示された理想に対して自分たちの理想を言語化してもらうところを繰り返し、泥臭く会話をしながら、進めていくってところが、いい感じで進んでいるTIPSになると振り返っています。」
過去のData Engineering Studyのアーカイブ動画
Data Engineering Studyは月に1回程度のペースで、データエンジニア・データアナリストを中心としたデータに関わるすべての人に向けた勉強会を実施しております。
当日ライブ配信では、リアルタイムでいただいた質疑応答をしながらワイワイ楽しんでデータについて学んでおります。
過去のアーカイブもYoutube上にございますので、ぜひご覧ください。
https://www.youtube.com/@dataengineeringstudy6866/featured
trocco®は、ETL/データ転送・データマート生成・ジョブ管理・データガバナンスなどのデータエンジニアリング領域をカバーした、分析基盤構築・運用の支援SaaSです。データの連携・整備・運用を効率的に進めていきたいとお考えの方や、プロダクトにご興味のある方はぜひ資料をご請求ください。。
