
今回の第17回Data Engineering Studyでは6人のデータエンジニアの方をお招きし、今年1年の取り組みについて振り返っていただきました。
いずれの振り返りもテーマは様々ですが、今日のデータエンジニアリング業界におけるホットでリアルな取り組みに触れられる内容となっております。
当日の発表内容はこちらになります。
LT1「Data Product Manager? / データプロダクトマネージャーとは?」
引用:廣瀬智史、「Data Product Manager? / データプロダクトマネージャーとは?」、https://speakerdeck.com/satoshihirose/detapurodakutomaneziyatoha
トレジャーデータ株式会社にてプロダクトマネージャーを務める廣瀬智史氏から、データに特化し、テクニカルな要素を理解できるプロダクトマネージャーとして、データプロダクトマネージャーというロールについてご紹介いただきました。
Senior Product Manager, Treasure Data
廣瀬智史氏
twitterアカウント
Data Product? Data as Product?

廣瀬 智史氏:「まずData as Productという言葉がありますよと。これはデータメッシュの文脈でよく使われるフレーズで、データをプロダクトの付属物ではなくプロダクトそのものとして扱うことで、価値を高めていきましょうという意味を持ったキーワードになります。データをプロダクトとして扱うことでタスクや責任が明確になったり、プロダクトとして品質の向上が図られたり、投資が促進されたりとアカウンタビリティがわかりやすくなるというのが良さだと思います。
Data Productというのは、まぁ業界で特に一意に文脈があるわけではないと思いますが、「データの活用を通じてユーザーの目標達成を促進するプロダクト」とされています。これに従うと、Data Productはデータとアプリケーションを指すのに対して、Data as Productはデータそのものを指すので、Data Productの方が概念としては広そうです。
また、こういった定義だと、Data Productは社内プロダクトも含んでいますが、社内に閉じたプロダクトでもPMのプラクティスを適応するのは十分意味があるので、(社内プロダクト)も含んでいいのではと思います。」
Data Product Manager?

廣瀬 智史氏:「これを踏まえると、データプロダクトマネージャー(DPM)というのがあってもいいのではないかという話になります。少し聞き慣れない言葉かもしれませんが、一言で言うとビジネス目標達成に必要なData Productを戦略的に開発し、市場に投入してサポート及び改善をするロールです。
PMというと様々ありますが、DPMは領域特化版のPMの一種だといえます。一般的に、プロダクトマネジメントというのは、非常に汎用的なプロセスを指すと思いますが、シードフェーズやスタートアップのPMと大企業のPMがフォーカスすることは同じではないので、領域によって名前が分割されている方が、やることが明確になっていいと思います。
こういったロールがあるといいという背景に、ビジネス上のデータの価値が増えており、Data Productが必要な場面が増えており、その中でデータの利活用や管理に当たるようなPMのロールの役割が大きくなっています。既にPMやデータエンジニアの人がこういった職責を担っている組織は多いと思うが、名前付けは重要だと思うので、こういう職分がありうるんじゃないかと認識されたり、可視化されているだけでも一定の視野が変わっていいことなのではないかと考えています。」

廣瀬 智史氏:「通常のPMとDPMで何が異なる点かというと、通常のPM業務とData Product特有のデータマネジメントへの理解が要求されるのが違いだと考えています。データ自体のリライアビリティとオブザーバリティを気にしたり、Data Productのスケーラビリティとエクステンシビリティ、ユーザービリティを確認したり、またそういう議論にフォーカスするようになります。特に、データエンジニアやアナリティクスエンジニアやソフトウェアエンジニアとの協働が求められます。」

廣瀬 智史氏:「そういうロールがフォーカスする領域の話になったときに、それはデータマネジメント領域になるのではという声が上がります。データマネジメントやデータガバナンスの領域はデータをどう管理するかといった守りに寄ったトピックが多いです。一方、Data Productはユーザーの目標達成に焦点を当てたデータ利活用の文脈で使われることが多く、どちらかというと攻めの視点で語られることが多く、フォーカスする視点の違いがあります。DPMやData Productの開発には自社のビジネスとデータ、一般的なデータ管理の両面に明るい人材が当たるとスムーズにいくとおもいます。
まとめ

廣瀬 智史氏:「まとめると、Data as Productはデータをプロダクトとして扱い、価値を高めていきましょうという考え方で、Data Productはデータの活用を通じてユーザーの目標達成を促進するプロダクトを指します。背景としてデータの価値が増してData Productも増えていく中で、データの利活用・管理に明るいPMロールのニーズが増えてきており、DPMはビジネス目標達成に必要なData Productを戦略的に開発し、市場に投入し、サポート及び改善をするロールであると、今回DPMというロールを紹介させていただきました。」
LT2「データの“守り”を固めた2022」
引用:河野匠真、「データの”守り”を固めた2022」、https://speakerdeck.com/takumakouno/detano-shou-ri-wogu-meta2022 より
株式会社Luupにてデータエンジニアリングを務める河野匠真氏からはLuupのデータ基盤をどのように進化させてきたかお話しいただきました。
Data Enginner, Luup,Inc.
河野匠真氏
twitterアカウント
Luupのデータとデータ基盤

河野 匠真氏:「Luupのデータ基盤は1点目のポイントとして、自転車・キックボード・アプリなどのデータはGoogleのクラウドファンクションで処理をして、BigQueryにデータを流す形になっています。2点目は、アプリの情報については、Firestoreに入れて、Firestoreからストリーミングの処理を経てBigQueryに流す形をとっています。」
データ基盤の課題

河野 匠真氏:「今年のデータエンジニアリングチームがどういったところに課題を感じていたかというと、1つめは「そもそもデータがどこにあるかわからない」こと、2つめは「BigQueryにデータは集まっているがRawデータはそのまま使えない」ことでした。」
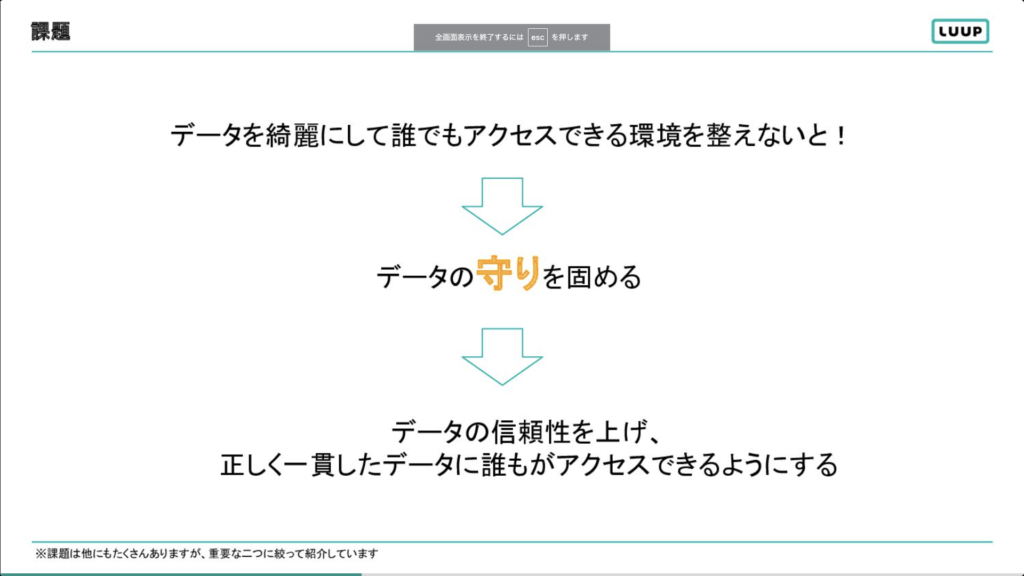
河野 匠真氏:「今年はデータをきれいにして誰でもアクセル出来る環境を整えることが大切だと考えました。そのため、データの守りを固めようという方針になりました。なお守りの定義は「データの信頼性を上げて。正しく一貫したデータに誰でもアクセスできるようにする」ことでした。」
1つめの課題「データがどこにあるかわからない」

河野 匠真氏:「BigQueryにデータが集まる状態にはなっていますが、どういう形で、どこのテーブルにデータが入っているかはエンジニアしかわからない状態でした。データを見るのはエンジニア以外の人も多く、ドキュメントがないためエンジニア以外がSQLを書きたいとなった時に対応できませんでした。

河野 匠真氏:「これはどのように解決したかというと、データカタログを用意することで解決しました。注意したポイントとして、ターゲットとしてエンジニアでなくとも簡単に使えるようなツールでないと使ってもらえないので、Notionのデータベースを採用しました。これによってデータがどこにあって、誰が作成して、いつどれくらいの頻度で更新される等の情報が誰でも確認できるようになりました。」
2つめの課題「Rawデータがそのまま使えない」

河野 匠真氏:「アプリのデータがFirestoreを経由してBigQueryに送られる形をとっているが、その過程のデータはJson形式のデータであるため、複雑なSQLが必要になります。Firestoreから送られるデータは(データの更新)頻度が高いものもあるので、BigQueryに入るRawデータが非常に大きくなっていました。また、Rawデータにクエリを書いた際に、定義が決まっていないので、書いた人によってSQLが代わってしまい、データが異なるという問題も生じていました。」

河野 匠真氏:「解決策として3つのポイントを実施しました。1つめは安定した基盤を構築する必要があったのでGoogle Cloudのエアコンポーザーを導入して、安定したデータ処理環境を構築したこと。
2つめに、定義ごとにデータの処理層を用意しました。これは一般的に言われるデータレイク、DWH(データウェアハウス)、データマートの三層構造を採用し、それぞれの層を用意することによってクエリ容量を削減、データマートの整合性を担保できるようになりました。そしてデータマートを用意することで非エンジニアも簡単なSQLでデータを取れるようにしました。以上3点を実施して、Rawデータ使えない問題を解決しました。」

河野 匠真氏:「結果として4つのことが見えるようになってきました。ダッシュボード毎にデータが異なるといったデータ不整合を防げるようになりました。クエリの容量を半分くらいまで下げることができました。簡単なSQLでデータが取れるようになりました。どういうデータが存在するのかを誰でも気軽に確認できるようになりました。とはいえ、構築完了したのが1ヶ月前なので新しい結果が今後出てくると思います。」
今後実現したいこと

河野 匠真氏:「今後はデータの”攻め”の部分に着手していきたいです。データの可用性を上げて、データの作り得る価値を最大化していくことを来年からやりたいです。例えばMap Visualizationの拡充、自転車やキックボードなどのIoTデバイスのログの情報を全て分析に扱えてるわけではないので、拡充と整備、そして会社全体のデータリテラシーの向上を図っていきたいです。」
まとめ

河野 匠真氏:「まとめとしては、データの守り・信頼性を上げて一貫したデータに誰でもアクセスできるようにすることに徹した年でした。」
LT3「dbt日本コミュニティの立ち上げと10Xでdbtの実践を行った2022」
引用:瀧本晋也、「dbt日本コミュニティの立ち上げと10Xでdbtの実践を行った2022」、https://speakerdeck.com/10xinc/dbtri-ben-komiyuniteinoli-tishang-geto-10xdedbtnoshi-jian-woxing-tuta2022
株式会社10Xにてアナリティクスエンジニアを務める瀧本晋也氏からは近年注目のツールであるdbtの活用について話していただきました。
Analytics Engineer at 10X
瀧本 晋也氏
twitterアカウント
dbtとは

https://speakerdeck.com/10xinc/dbtri-ben-komiyuniteinoli-tishang-geto-10xdedbtnoshi-jian-woxing-tuta2022 より

https://speakerdeck.com/10xinc/dbtri-ben-komiyuniteinoli-tishang-geto-10xdedbtnoshi-jian-woxing-tuta2022 より
瀧本 晋也氏:「dbtとはData Build Toolの略で、dbt Labs社とdbtコミュニティが開発するOSSで、基本的にはSQLをベースにしています。ソフトウェアエンジニアリングのベストプラクティスを取り入れながら開発できるツールで、ELTのパイプラインだったり、処理の中でDWHに蓄積したものを変換してデータ活用・DWHのデータソースとして利用するシーンで変換層の処理をしてくれるものです。
実際、dbtはデータ基盤をスモールスタートでチャレンジしてみたいだとか、データモデリングの際の複雑なパイプラインやチーム開発のSQLの難しさなどを解決していってくれるものです。またdbtはtrocco®でもリリースされて使えるようになっています。」
dbtコミュニティの活動

https://speakerdeck.com/10xinc/dbtri-ben-komiyuniteinoli-tishang-geto-10xdedbtnoshi-jian-woxing-tuta2022 より
瀧本 晋也氏:「dbt公式Slackコミュニティの中で、東京リージョンの開発を行いました。当時の観測範囲ではクラスメソッドの玉井さんやUbieの石川さんが先行してウォッチ&コミットしていらしたが、自分も使っていく中で日本のユーザーの数は少なかったので、利用者の数や良さを広めていきたいと思って始めました。いまでは他のローカルチャンネルのうち5位までの成長を遂げ、4万人近くいるユーザーのうち東京リージョンのユーザーは292人にまで増えました。そしてdbtCoalesceのイベントでも東京が紹介されていて嬉しかったです。
その他、dbt Tokyo Meetupというイベントを開催し、年に4回企画して毎回盛況です。またdbtの入門記事の公開を行い、表示回数も右肩上がりにきています。」
10Xでdbtを使ってDWHやデータプロダクトを作った話

https://speakerdeck.com/10xinc/dbtri-ben-komiyuniteinoli-tishang-geto-10xdedbtnoshi-jian-woxing-tuta2022 より
瀧本 晋也氏:「10Xでは今年の初頭からDWHやデータマート構築用のパイプラインとしてdbtを活用してきました。データレイク層からGatewayへ、DWHをまとめてMartを作ってBIツールで参照するという流れです。これは初期のDWHで、この後にVaultや、よりメトリクスを活用するような基盤が構築されてきています。」

https://speakerdeck.com/10xinc/dbtri-ben-komiyuniteinoli-tishang-geto-10xdedbtnoshi-jian-woxing-tuta2022 より
瀧本 晋也氏:「直近取り組んでいるテーマとして、ネットスーパーの商品を購入する際に、データを作って並べる必要がある、そこの部分に関して各パートナーからスーパーの基幹データをもとに、各店舗ごとにどういう商品がどのくらいあって、どういう売価で売るべきかといった、アプリケーション・パイプラインを構築しているが、試行錯誤していく中でアーキテクチャとして複雑になったり、属人性が発生したりした。改めて業務をもっと理解して最適なパイプラインを組むか、どのようにレイヤリングしていくかを現場に行ってスタッフさんが携わる業務を体験しながら、自分が提供しているプロダクトが何が問題なのかを確認し、それを踏まえながら設計しました。」

https://speakerdeck.com/10xinc/dbtri-ben-komiyuniteinoli-tishang-geto-10xdedbtnoshi-jian-woxing-tuta2022 より
瀧本 晋也氏:「実際いま店舗で動いているようなアーキテクチャをdbtをもとに設計しました。併せてこのアーキテクチャはアプリケーションが必要とするデータを生成する責務を負うデータプロダクトなので、一歩間違えると大変な問題になります。このパイプラインをいかに品質高く動かしていくかということに加えて、プロダクトが動いている状態で開発を行っていく両輪を上手く回していくために様々なテストや手法を取り入れています。」

https://speakerdeck.com/10xinc/dbtri-ben-komiyuniteinoli-tishang-geto-10xdedbtnoshi-jian-woxing-tuta2022 より
瀧本 晋也氏:「また社内でデータプロダクト部が発足し、なかでも先ほど廣瀬さんがお話したデータプロダクトのPMだったり、データアナリストにスキルセットは近いがデータをどのように作っていくかの職種であるデータプロダクトエンジニアという名のJDを作りました。」
来年への抱負

https://speakerdeck.com/10xinc/dbtri-ben-komiyuniteinoli-tishang-geto-10xdedbtnoshi-jian-woxing-tuta2022 より
瀧本 晋也氏:「dbtコミュニティに関してはより活用のシーンが広がっていくことを支援したいし、色んな人や企業の取組が共有されるような取り組みをしたいです。また10XではDWHはもちろん、データプロダクトを作る上でdbtを活用していますが、よりデータ品質を向上させるためのテストや検知、またアナリティクスエンジニアやデータプロダクトエンジニアがチームで開発するためのナレッジ等を深めて共有していきたいです。」
LT4「dbtでアトリビューション分析」
引用:小林寛和、「dbtでアトリビューション分析」
https://speakerdeck.com/hiro_koba_jp/dbtdeatoribiyusiyonfen-xi より
株式会社primeNumberにてCPOを務め、データ分析基盤構築サービスtrocco®のプロダクトオーナーとして開発を主導する小林寛和氏にはdbtを活用したマーケティング施策のアトリビューション分析についてお話しいただきました。
primeNumber, Inc. CPO
小林 寛和氏
twitterアカウント
プロジェクトの背景

https://speakerdeck.com/hiro_koba_jp/dbtdeatoribiyusiyonfen-xi より

https://speakerdeck.com/hiro_koba_jp/dbtdeatoribiyusiyonfen-xi より
小林 寛和氏:「弊社は10月末が期末で、期末のタイミングでマーケティング施策の効果を計測したかったが「最後に見られた広告」だけが評価されていました。
最後だけじゃなくて、ユーザーが「最初に見た」施策の効果も測定したいというのがプロジェクトの背景にありました。
例えば「Twitter広告」→「Facebook広告」→「自然検索」→「問い合わせ」→「契約」という流れで契約に至ったとき、成約がどこのチャネルの成果なのかがわからないというのがありました。一般的には最後の「自然検索」だけが評価されがちですが、たとえば「Twitter広告」や「Facebook広告」「自然検索」を均等に評価してみるなどのアイデアがアトリビューション分析です。
プロジェクトをどう進めたか

https://speakerdeck.com/hiro_koba_jp/dbtdeatoribiyusiyonfen-xi より
小林 寛和氏:「前提として、釈迦に説法かもしれませんがデータモデリングとデータモデリングツールは違います。データのモデリングってそもそもなんなのかというと例えばスタースキーマやスノーフレークスキーマ、最近だとData Vault2.0などモデリングの設計思想みたいなものに基づいて、じゃあ実際に今回のアトリビューション分析を行うためのテーブルであったり、中間テーブルをどのように設計していくかというのがデータのモデリングです。それを実装するのがデータモデリングツールで、dbtやDataform、LookMLにも似た機能があったと思います。またSQLを生で書いてAirflowやdigdakといったワークフローツールからキックするなどでも実現可能かなと思います。
こういった2つの話があるかなという前提のものと、プロジェクトの流れとしてはデータモデルの設計を最初に行いました。
その次に行ったのがツールの選定ですね、おわかりかと思いますがdbtを選定し、実装して結果の検証という流れで行いました。」

https://speakerdeck.com/hiro_koba_jp/dbtdeatoribiyusiyonfen-xi より
小林 寛和氏:「データモデルの設計ですが、今回はスタースキーマっぽいものを設計してみました。中心にマーケ効果というファクトテーブルを配置し、実際には費用がいくらかかったのかですとか、クリックがどれくらい発生したのかというのを列として持っています。そのディメンション、分析の軸となるディメンションは日付や流入チャネルやブラウザ、セッションというものを別テーブルに切り出してID参照するような形でスタースキーマっぽいものを作りました。
特に効果があったところでいうとこの流入チャネルのところですね。広告の分析とか、まぁそういったことを売上の分析するとどの経路で、Google広告で知った人なのか、そういう流入チャネルで分析すること結構あると思うんですけど、今回マーケチームで協力して流入チャネルのチャネルマスタみたいなのをちゃんと整備し、そこをディメンションテーブルとして参照するような形でマーケ効果を、成果を出したりしてました。もちろんマーケと目線が揃ったよねって話がありますし、流入チャネルテーブル・マスタテーブルを再利用可能になったという点が成果かなと思っています。

https://speakerdeck.com/hiro_koba_jp/dbtdeatoribiyusiyonfen-xi より
小林 寛和氏:「dbtの実装についてはこの後話すとして、結果の検証もきちんと行いました。
まずdbをt使ってたのでdbtのテストを活用しました。今回売上など生生しい値を出してるのでテストきちんと書かないとねというのがありました。もうひとつ大事だったのがマーケの人にデバッグを手伝ってもらったことでした。やはり現場の生の人じゃないとわからない観点とかデータの中身の話とかあって、なんか違うかもって言ってもらって調べてみたらSQL間違ってたとかって実際あったので、マーケの人に、現場の人にデータ見てもらうことの重要性に気づくことができました。」
dbtの実装・実行環境

https://speakerdeck.com/hiro_koba_jp/dbtdeatoribiyusiyonfen-xi より
小林 寛和氏:「ではdbtの実装や実行環境どうやって用意したのかという話に移らせていただきます。ちょっと細かい話になってしまいますが、抽象的な図としてこのようなデータの処理プロセスを設けました。
左上から行きます。まず広告データとってこなければいけなかったので広告データをETLしてとってくるところ、また売上データもそこに紐付けたかったので売上データをETLするところがまずあります。それから中間テーブルというか広告データと売上データを紐付けた広告売上データのテーブルを作成しました。
それから左下、アトリビューションはユーザーの行動ログが必要なのでユーザーの行動ログをETLしてきて、それをPVの単位のデータをセッションぐらいの単位にしたものを中間テーブルとして用意しました。この広告売上データとセッションデータを合わせた中間テーブルを作成し、これがいわゆるアトリビューションのパスですね、ユーザーがこれとこれとこれのチャネルを経由してこの売上に至りました、というようなものを作り上げました。
そして最後にそのテーブルをチャネルでグループバイして、チャネル別にアトリビューションを出すというような処理プロセスを踏んでいます。ちょっと細かいところは、もしかしたら今後アトリビューション分析のお話を講演するかもしれないのでウォッチしておいてください。」

https://speakerdeck.com/hiro_koba_jp/dbtdeatoribiyusiyonfen-xi より
小林 寛和氏:「で、実際にdbt上のテーブル構成というか、モデル構成こうなりましたみたいな図を今出しています。この図の内容を説明するっていうよりはこのテーブル設計何を参考にしたかっていうところなんですけれども、dbtにはドキュメントページにスタイルガイドベストプラクティスみたいなのがあるのでそれを参考にしたというのと、ただそれだけだと概念しかわからなかったのでgitlabかなんかが上げているオープンソースの公開されているリポジトリでdbtの実際のソースコードでどんなディレクトリ切っているのかみたいなのを参考にしていました。」

https://speakerdeck.com/hiro_koba_jp/dbtdeatoribiyusiyonfen-xi より
小林 寛和氏:「また実行環境の話ですね。実行環境を用意するときに自前で作るかdbtクラウド使うかを悩んだんですけれども、dbtクラウドを最初に選んだんですね。ただ他に色々なことをやりたくなってきちゃって、例えば広告データのETLさっきあったと思うんですけれども、あれとdbtの流れを依存関係ちゃんと作りたくて、前がこけたらdbt動かさないみたいなことやりたくなったり、またdbt実行した後にデータを検算したりSlacokで通知飛ばすみたいなのもやりたくなっちゃって、dbt on trocco®は実はこのタイミングで作ったりしてました。」

https://speakerdeck.com/hiro_koba_jp/dbtdeatoribiyusiyonfen-xi より
小林 寛和氏:「で、トロッコのdbt連携機能なんですけれどもこんな感じでtrocco®のワークフロー上でETLを最初動かしてdbt動かして検算行ってリバースETLなんかもやっちゃってSlack通知を行って、というような流れを実際に今弊社のtrocco®上で動かしています。」
まとめと今後のトライ

https://speakerdeck.com/hiro_koba_jp/dbtdeatoribiyusiyonfen-xi より
小林 寛和氏:「今回は均等配分モデルという売り上げをチャンネルに均等に分散して配分するモデルを選んだんですが、どのモデルがいいのかとかまたその効果検証みたいなのをやっていきたいなと思うのと、 売り上げデータとか使うのでちゃんとテスト書いていきたいです。まだ全然カバレッジまで低いのでgreat expectationsとかを使って実際に溜まってるデータのテストを書いていきたいなと思ってます。
また今回スタースキームを使ってディメンションテーブルいっぱいできたんですけれども、その履歴も管理しなきゃいけないよねっていうところで、Slowly Changing Dimension(SCD)の実装、みたいなのも今後トライしたいなと思っております。」
LT5「2022年のLINE Data Platform室」
LINE株式会社にてデータエンジニアリングセンター内データプラットフォーム室、IU Hadoopチームでエンジニアリングマネージャーを務める小野博紀氏は社内のデータ分析基盤IUをSpark3.0へ移行させるプロジェクトについて振り返ってお話しいただきました。
Data Engineering Manager, LINE, Inc.
小野 博紀氏
twitterアカウント
LINEの分析基盤IU

https://youtu.be/Tet9zUXVJ2k?t より
小野 博紀氏:「はじめにLINEの分析基盤について簡単に紹介させてください。LINEにはIUって呼ばれる全社的なデータプラットフォームが存在しています。私のいる部署はこのIUの運用とか、開発をしている部署になります。LINE社内のデータがこのIUの中に集約されているイメージになります。このIUの中にデータプラットフォーム自体は2019年から構築をしていて、そこから3年経っていまはどうやって最適化するかとか可視化や整理といった、ちょっと仕事の質が変わってきたかなと思っています。
今日の発表はこの最適化、あとは可視化整理に関わるプロジェクトの一部を紹介しようと思っています。」
Spark3移行プロジェクト

https://youtu.be/Tet9zUXVJ2k?t より
小野 博紀氏:「1つめの最適化に関するプロジェクトにはSpark3のプロジェクトがありました。概要としては既存のSparkの処理をSpark3に移行するプロジェクトになります。なぜやったかというと、Spark3から多くのパフォーマンス改善が導入されていたからという理由が一番大きいです。特にこの改善の中でも嬉しかったものは自動的処理が最適化されるような機能です。これはSpark3のAQEの機能の一部になりますが、なぜ(この機能が嬉しかった)かっていうとSkewed Dataによるパフォーマンス劣化が度々発生していたからです。Skewed Dataっていうのは偏りのあるデータっていう意味なんですが、イメージとしては処理中にホットスポットが出来ちゃって処理全体が長くなってしまうと言った問題になります。Spark3を使うとこの辺をよしなにやってくれるので、とても嬉しい機能になっています。
あとはSpark3.2からはSpark2の環境と同居しやすくなったというものがあります。IUの中に自体を使っているユーザーはかなりの人数がいるので、明日からSpark2やめますというのは現実的ではないです。なのでSpark3とSpark2を同時に使えるようになったのはこの大規模な移行のきっかけの一つになりました。
実際何をやったかと言うと、Spark3への移動の呼びかけの他に、いま何パーセントの人がSpark2使っています、何パーセントの人がSpark3使っていますといった移行の進捗管理とかも行っていました。そしてこのプロジェクトで大変だったこととしては、一つは脆弱性の対応です。あとはユーザーへの説明があって、Spark3についてわからない人が多いのでその説明にも結構労力を使いました。」
Showbackプロジェクト

https://youtu.be/Tet9zUXVJ2k?t より
小野 博紀氏:「次に可視化の文脈でShowbackプロジェクトっていうものを選びました。概要はデータプラットフォームを使った料金額をユーザーに提示しようというプロジェクトです。背景としては、効率の悪い処理を改善するとか、いらないデータは捨てるとか、最適なプラットフォームの使い方をユーザー自信が考えるようにしたかったというものがあります。
具体的には誰がどのくらいデータを使ったとか、何か保存しているかを過去分まで集計するとか、処理した時にどのくらいメモリを使ったかっていうのを取得するためにプラグイン開発をしたりしました。あともう一つは料金の設計です。AWSとかGCPとかを使ってると多分あんまり意識しないかもしれませんが、自前で(プラットフォームを)作っていると0から料金を考えるイメージになります。やろうと思えば正直なんでも出来るっていうか無限に考慮することがあるので、落とし所を見つける作業はかなり大変でした。
KonMariプロジェクト

https://youtu.be/Tet9zUXVJ2k?t より
小野 博紀氏:「最後は整理の文脈で、KonMariプロジェクトっていうものが弊社では進んでいます。概要としては近藤麻理恵さん流の整理方法でデータを整理しようといったものになります。背景としてはデータ量が年々増加していて、明らかに将来データの容量を超えることがわかっている状況だったというのと、正直使っているか使っていないかわからないデータが沢山あり、要は整理されていない状態だったということで、KonMariメソッドを使って整理しようという流れになりました。
このプロジェクトでやることはいらないものを捨てることです。実際にデータを捨てると結構危ないので、要らないものは捨てる勢いで処理するといったイメージになります。具体的には、参照されていないデータを検出して、Amazon S3にアーカイブするといったものです。もう一つはまだ実現できていないんですが、ユーザーがデータを整理できる環境をと考えています。具体的にはユーザーがデータにタグを付けられるようにしたいなと考えています。これはテスト用のデータだとか必須のデータだとか見るもの要らないものとを整頓するイメージです。で、これは判断する時に当然お金の話も考えると思うので、Showbackプロジェクトもここに貢献してくるかなと考えています。」
さいごに

https://youtu.be/Tet9zUXVJ2k?t より
小野 博紀氏:「最後にデータプラットフォーム室で活躍している人についてちょっと話したいと思います。ここ数年でデータエンジニアとして経験がない人も一緒に働き始めることがありました。これは結構私の考えが強く入ってるんですが、活躍する人には主に2パターンあると思っていて、深堀りして調べる人と想像力がある人です。深堀りに関してはパフォーマンスチューニングのときにLinxとかKernelにたどり着ける人、また想像力については、データプラットフォームの領域ですと分散処理が多いので、頭の中でこうデータがこうやって動いてって想像できる方が強いかなと考えています。最初に仕事の毛色が変わってきたっていう話があるんですが、活躍する人もそれに伴って少し変わってきていると感じています。技術力は当然今でも大きな活躍をしているんですが、ただ技術力だけじゃなくて、現状の分析とかプランニングとかこうソフトスキルが強い人の活躍が結構目立ってきている2022年でした。以上です。ありがとうございました。」
LT6「『エンタープライズ』という言葉の重さ 〜Data Vault 2.0をやめた2022年冬〜」
引用:池田将士、「『エンタープライズ』という言葉の重さ 〜Data Vault 2.0をやめた2022年冬〜」、https://speakerdeck.com/mashiike/entapuraizu-toiuyan-xie-nozhong-sa-data-vault-2-dot-0woyameta2022nian-dong より
株式会社カヤックにてSRE事業部に所属する池田将士氏からはデータモデリングに関する手法であるData Vault 2.0についての取り組みを振り返ってお話しいただきました。。
SRE Division, KAYAC Inc.
池田 将士氏
twitterアカウント
Data Vault 2.0とは

小池 将士氏:「みなさんはData Vault 2.0知ってますかっていう話なんですけど、スケーラブルなエンタープライズDWHを設計できるモデリング手法っていうふうなことを聞いたりします。正確にはモデリング手法ではなくもっと包括的な手法なんですけど、長くなるので一旦省略ということで。要はアジャイルで監査性があってスケールしやすいデータウェアハウスを構築できる手法みたいな暴論を投げかけるんですけど、まぁいい手法です。とてもいい手法です。」
Data Vault 2.0を導入してみた結果


小池 将士氏:「で、これを15ヶ月前にTonamelっていうサービスで入れましたって発表をしたんですね。スクラッチでマクロを書いてData Vault2.0を実践していったという話です。
15ヶ月前の状況とするとプロダクト側でサーバーサイドエンジニアが3人で、データソースとしてDynamoDBとAuroraを連携してデータエンジニアが0.6人、まぁ私一人で保管検討っていう感じでいました。Data Vault2.0を入れてデータソースが2つに増えたんですね。dynamo DB増えて。なので複数のデータソース対応できていいなと思っていたんですね。」


小池 将士氏:「で、一年前の1月の状況になるとサーバーサイドエンジニアが4人に増えてサービス数ももう2つ増えて倍になったんですね。そうすると連携先増えても楽に対応できていいやんいいやんってなったんですよ。そしてサーバーサイドエンジニアがもうひとり増えてサービスももう一個増えて、さらにスプレッドシートとか色々データを同期し始めたんですよ。これが6月ごろですね。」

小池 将士氏:「そしてちょっとまってプロダクトの開発めっちゃ速くない?ちょっと待って待ってって状況になったんですよ。そしてちょっと前の9月ぐらいの状況になるともうひとりサーバーサイドエンジニアが増えて6人になって、うん。お気づきでしょうか、プロダクト開発チームはスケールしてるんですけど、データチームは全然スケールしてないんですね。そしてデータ基盤の保守に手が回らなくなってしまいました。
エンタープライズ向けの手法の苦労

小池 将士氏:「どうしてこうなったかというと、データエンジニアが採用出来なかったっていうのもそうなんですが、このData Vault 2.0という手法が結構ネックなところがありまして、ここエンタープライズって言葉が入ってるんですけど、エンタープライズってことは大きい会社向けなんですよね。これ言わずもがなですけどうちは中小企業です。で、中小企業でもさらに一個のプロダクトなんでもっと小さいんですよ。そんなところがエンタープライズ向けのものをやってみたらどこがキツかったかって話をすると、ここなんですよ。」

小池 将士氏:「このステージングレイヤーからステージレイヤーにいろんなデータをガチャンとまとめてそこからその後はブリンクでライトって3つに分けるんですけど、密結合になっているものを疎結合に治すって結構重労働なんですね。もう大変なんですよ。さらにソースデータって日々変わっていくんで整合性を履歴として保証しているのがものすごく大変なんです。この後時間が経つにつれてこのVaultって領域の保守難度が高くなって大変なんです。物量も多くなるんですよ。
で、少なくともやってみた感じだと1つのソースシステムに0.5人、要するに2つシステムがあったらそれを1人で担当するくらいの規模感じゃないと厳しいなぁっていう感じなんですね。」
Data Vault 2.0からの脱却


小池 将士氏:「で、どうするかって話なんですけど、生産性上げたいです開発効率上げたいですという話で、ソフトウェアエンジニアリングの世界ではMVCアーキテクチャーっていうモデル、Ruby on Railsっていうのがあるんですね。これは柔軟性になんか出てくるとか言うんですけど、こういうのがあるんですよ。なので柔軟性に関しては一旦妥協、データマートとステージングを密結合させようって言ってこのVault層っていうのを一緒にまとめたモデルを作ったんですね。はい、Data Vault 2.0やめました。」

小池 将士氏:「で、これ何って話をしてくると、あ、これdbtのスタイルガイド通りじゃんっていう話なんですよ。Data Vault 2.0やめて全部密結合させてみたら気がついたらdbtスタイルガイドというお手本通りになってたっていう話ですね。

小池 将士氏:「ということでまとめると、中小企業、もっと小さいようなデータエンジニア1人くらいのところでData Vaultやった結果、手が回らなくなってやめましたと。気がついたらdbtスタイルガイドのとおりになってましたと。
なのでエンタープライズと名がついているものっていうのはデータチームがスケールするんだったらいい選択肢なんですけど、スケールしないんだったら覚悟してくださいって話ですね。」
過去のData Engineering Studyのアーカイブ動画
Data Engineering Studyは2月に1回程度のペースで、データエンジニア・データアナリストを中心としたデータに関わるすべての人に向けた勉強会を実施しております。
当日ライブ配信では、リアルタイムでいただいた質疑応答をしながらワイワイ楽しんでデータについて学んでおります。
過去のアーカイブもYoutube上にございますので、ぜひご覧ください。
https://www.youtube.com/channel/UCFde45ijA-G9zs7s2CuftRw
trocco®は、ETL/データ転送・データマート生成・ジョブ管理・データガバナンスなどのデータエンジニアリング領域をカバーした、分析基盤構築・運用の支援SaaSです。データの連携・整備・運用を効率的に進めていきたいとお考えの方や、プロダクトにご興味のある方はぜひ資料をご請求ください。
