
はじめに
近年、情報通信技術の発展に伴い我々が取り扱うデータ量は飛躍的に大きくなりました。データエンジニアと呼ばれるデータの専門職が登場し、データの活用法は限りなく広がりましたが、一方でデータをどう管理すればよいかというデータマネジメントもまた大きな課題のひとつです。
そんなデータマネジメントのひとつに、DWH(データウェアハウス)上でのデータ変換の流れ、DWH内に無数に点在するデータベース間の関係をどのように管理すればよいかという問題があります。このようなデータマネジメントを助けるツールのひとつが今回紹介するdbt(Data Build Tool)です。
dbt cloudとは
ETLという言葉のとおり、データ分析の世界ではデータベースからデータを抽出し、加工・変換作業を経て必要なデータだけをDWHへ統合するのが一般的な流れでした。ですが膨大な生データ(並び替えなどの操作をする前の一次データ)も高速処理が可能なDWHサービスが次々と登場したため、データを一旦そのままDWHへ格納し、加工・変換作業を経て再度DWH上の別のテーブルへ戻すというELTの流れも一般的になりつつあります。
dbtはこのELTにおけるT(Transformation:変換)作業を担うツールで、この作業そのもののハードルを下げる機能があるほか、記述したSQL(データベースに対する命令文)からDWH上のデータベース同士の関係を拾い、自動でモデル化するというデータモデリング機能があります。
dbtは中でも利用料金の有無で大きく2つに分けられます。無料で利用でき、コマンドラインから操作するOSS版、利用料金が発生し、GUI上で設定・操作するdbt cloudがあります。
OSS版は導入コストの面や、ノウハウがあれば自由に開発できる点、後者はSaaSサービスであるがゆえに保守運用の手間が要らず、また扱いやすいという点がメリットとして挙げられます。
dbtの機能
dbtの機能のなかでも特に特徴的なものをいくつか紹介します。
Gitリポジトリと連携したCI/CD機能
ソフトウェア分野では小規模な開発サイクルをスピーディーに回すアジャイルの手法が注目されつつあります。アジャイルを支える体制のひとつにCI/CDというものがあり、各エンジニアの書いたコードに対するテスト・本番環境へのデプロイをある程度自動化させて開発スピードを向上させたり、小刻みにリリースを繰り返すことで万が一エラーが発生した際の原因の特定を容易にする効果があります。
一方dbtでは連携したGitリポジトリにSQLをプルリクすることで、それを検知したdbtが自動的にSQLのチェックやそのSQLによる影響のテスト等を行います(CI機能)。またデプロイ用のジョブを設定することでデプロイまでを自動化することも可能です(CD機能)。各人のSQLをGitリポジトリ上でバージョン管理することも出来るなど、アジャイルの手法に近いデータエンジニアリングが可能です。
データは日々絶えず収集され、また社内のデータのニーズも常に変化するため、データエンジニアリングにおいても小規模な改修をスピーディーに回していくアジャイルの考えを部分的に取り入れられるdbtの機能は有効に働くのではないでしょうか。
SELECT文だけで高度なデータ変換が可能
dbtではデータベースの操作にSQLを使用します。ただしSQLにおけるSELECT文さえわかればある程度複雑なデータ加工も可能です。またJinjaを利用した柔軟な記述も可能で、データ加工のハードルを下げます。
データベースのメタデータ作成
あるデータについて、そのデータがどのようなデータかを説明するという”データについてのデータ“をメタデータといいます。dbtはあるデータベースがどのようなデータをもつのか、どのデータベースを加工して生まれたものなのかなどの情報をドキュメント化し、いわば”データベースのメタデータ”が簡単に出力可能です。
各データベースの情報が整理されていると、単にデータベース同士が区別しやすいというだけでなく、データベースの配置を最適化するためのデータモデリングに役立つという効果があります。
またユーザーが求めるデータベースを検索しやすくするデータカタログの仕組みという一面もあります。
SQL文中のREF関数からデータベース同士の関係を自動的に抽出
dbtはSQL文中のREF関数からデータベース同士の関係を自動的に抽出してモデル間の関係を図示します。これによりモデル同士の関係がわかりやすくなり、データリネージが向上します。
データリネージが向上するだけでなく、それにより現状のデータベースの配置を認識しやすくなるためこちらも上述のデータモデリングをサポートするという効果もあります。
依存関係を意識したデータの加工・変換
データは未加工の生データから複数の加工・変換を経てユーザーの求めるデータベースの形式に整えられます。このときそのデータの加工ラインの順番に沿ってSQLを実行していかないと正しいデータの加工結果が得られないため、複雑なデータ加工ほど手順には注意が必要です。
dbtでは先述のREF関数からデータベース間の依存関係を自動で認識しているため、ユーザーの手で実行の順番をハンドリングしなくとも一連のデータベースの加工を正しい手順で実行してくれます。
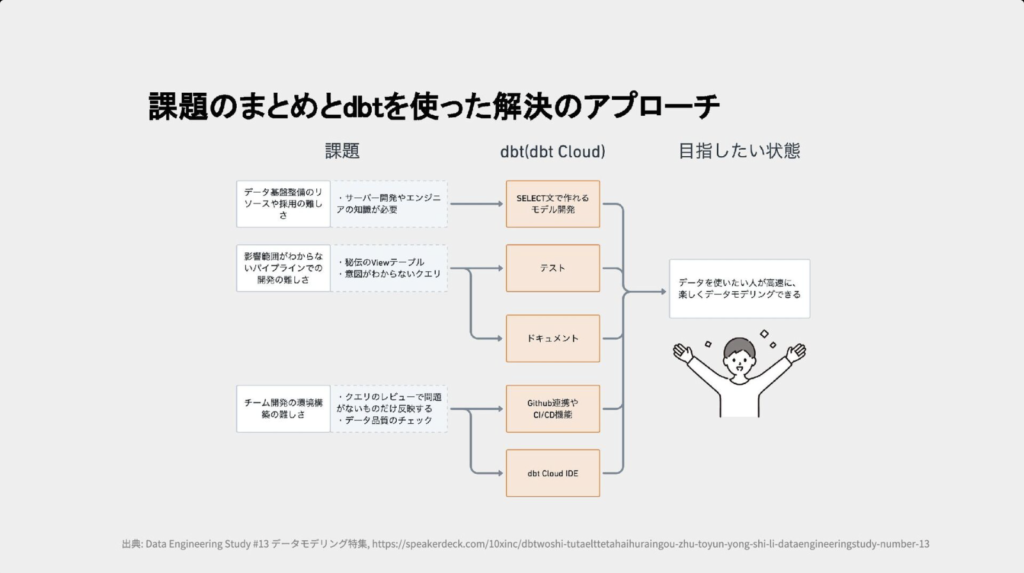
dbtの活用
dbtがDWHの活用を強力にサポートする機能を備えていることがわかったかと思います。
ですが、その一方で、仮にdbtを導入したとしてもDWHへのデータ統合の段階でつまづいてしまっていてはdbtを有効に活用することはできません。
また逆にDWHへのデータ統合をだけを楽にこなすことができてもデータを自在に加工・変換できなければ最適なデータ分析基盤は構築できません。
そこで弊社が提供するデータ分析基盤構築サービスtrocco®はdbt連携機能をリリースしました。
dbtとの連携によりdbtのコンソール画面に移動しなくともtrocco®の画面上でdbtジョブの設定が可能です。

また、データをDWHへ統合するまでのETLジョブに加え、DWH統合後のdbtジョブもtrocco®のワークフロー機能で管理することが出来るようになりました。

trocco®とdbt、双方の利点を活かしつつ、弱点を補い合うことでデータ分析基盤の構築を更に強力にサポートするツールとなりました。
まとめ
「DWHへのETL」「DWH上でのELT」、どちらもすべて自分で行うにはデータエンジニアリングの知識についてのキャッチアップ工数、分析基盤構築のコスト、その保守運用コストまで発生してしまいます。
しかし、非エンジニア圏の人がデータ分析を諦める必要はありません。
trocco®やdbtといった各種データエンジニアリングツールを活用し、誰もがデータの分析工程にフォーカスできる体制を整えてみてはいかがでしょうか。
なおtrocco®は無料プランの提供を開始しており、実際に試してから導入検討が可能です。
>troccoサービス紹介資料のダウンロード【無料】はこちら
ぜひご検討ください。
