
HubSpotとは
HubSpotはアメリカのHubSpot社が提供するマーケティングツールで、インバウンドマーケティングの考えに則ったマーケティング支援を行います。このようなマーケティングツールでは集めたデータからグラフや表といったデータの性質を視覚的にわかりやすくするためのツールを作成し、マーケティング戦略の立案に活用するということもあるでしょう。
ですがHubSpot標準のレポート機能だけでは不十分だったり、他のマーケティングツールや広告サービスのデータと組み合わせた横断的なデータ分析を行う際には、HubSpotのデータをDWH(データウェアハウス)へ統合し、連携したBIツール上で可視化を行うというデータ分析基盤の構築必要になります。
概要
今回はTROCCO®というデータ分析基盤構築サービスを利用してHubSpotのデータをGoogle BigQueryというDWHへ統合し、Looker Studio(旧:Googleデータポータル))を用いてデータの可視化を行います。

ゴール
HubSpotから取得したデータを↓画像のようにグラフをまとめます。また作成後はTROCCO®の機能により自動で最新値に更新することも可能です

こんな人におすすめ
- HubSpotを利用しており、分析基盤やデータウェアハウスへのデータ統合を考えている方
- 様々なCRMサイトの情報をまとめてひとつのサービスで管理したい
- 管理画面からデータ取得を行う作業に疲れている方
1. DWHと、データを転送する手段の決定
1-1. DWHの選定
まずはデータをどこに集約するか、DWH(データウェアハウス)を選定します。
- Google BigQuery
- Amazon Redshift
- MySQLやPostgreSQL
TROCCO®はいずれのサービスにも対応していますが、今回はGoogle BigQueryを利用することにします。
1-2. HubSpotのデータをGoogle BigQueryに転送する4つの方法
Google BigQueryにデータを集約することが決まったので、続いてはデータを転送するための手段を検討します。
1. HubSpotのデータを管理画面からエクスポートして、手動でGoogle BigQueryにアップロードする
2. HubSpotとGoogle BigQueryの各APIを利用したAPI連携を自分で実装する
3. Embulkを利用し、自分で環境構築する
4. TROCCO®️を利用して画面上の設定のみでデータの転送基盤を構築する
1 は単発の実行であれば問題はありませんが、日々更新され続けるデータを分析の度にその都度取り込むということを考えれば効率の良い運用を見込めそうにありません。
2 はまずはじめにAPIについての知識をキャッチアップし、APIを利用したプログラムを書く+環境構築の時間、それに加え運用中に発生したエラーへの対処といったコストが発生します。
3 も2 と同様にEmbulkを扱うにはデータエンジニアリングの専門的な知識が必要になり、自分で環境構築・運用を行う手間も発生します。加えてAPI連携のエラーと比べ発生するエラーの内容が少し専門的なため、対処が困難になるケースが考えられます。
そこで今回はEmbulkの課題も解決し、複雑なプログラムを書かずに画面上の設定のみで作業が完結する、4 のTROCCO®️を利用します。
2. TROCCO®️でHubSpot → Google BigQueryの転送自動化
2-0. 事前準備
データの転送のためにはTROCCO®️のアカウント・HubSpotのアカウント、Google BigQueryとGoogleデータポータルを使用するGoogleアカウントが必要です。
無料トライアルを実施しているので、事前に申し込み・登録しておきましょう。
https://trocco.io/lp/inquiry_free.html
2-1. 転送元・転送先を決定
TROCCO®️にアクセスして、ダッシュボードから「転送設定を作成」のボタンを押します。
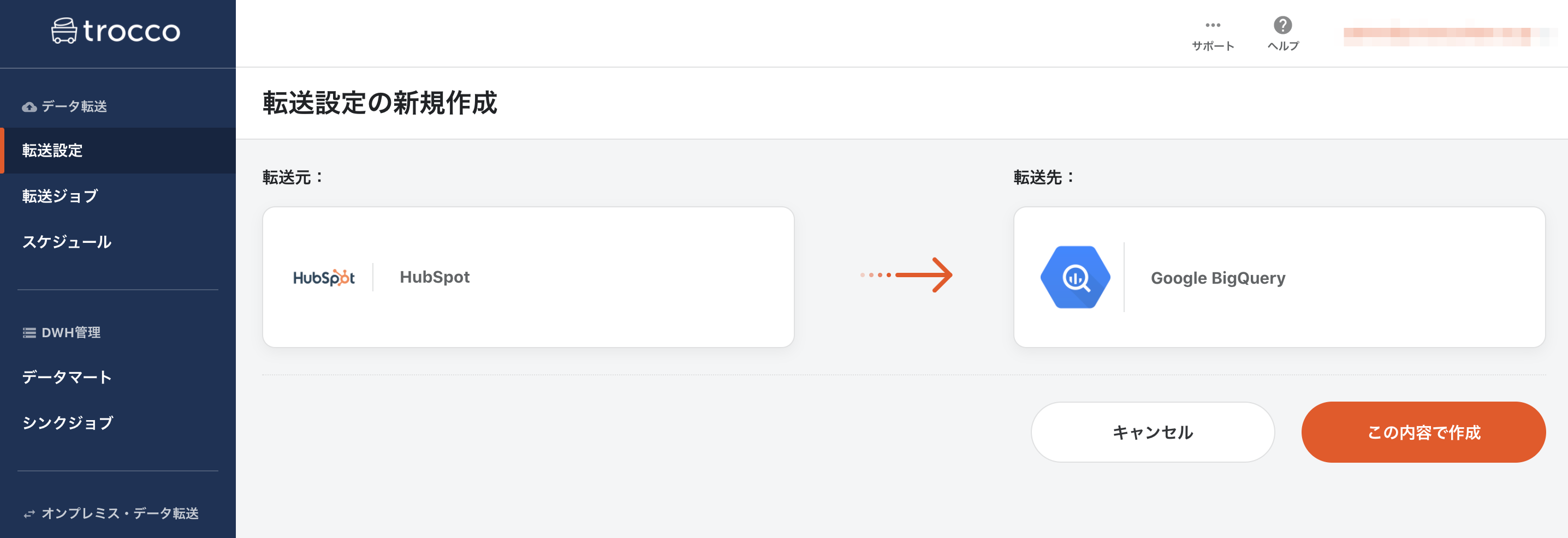
転送元に「HubSpot」、転送先に「Google BigQuery」を選択して「この内容で作成」ボタンを押します。
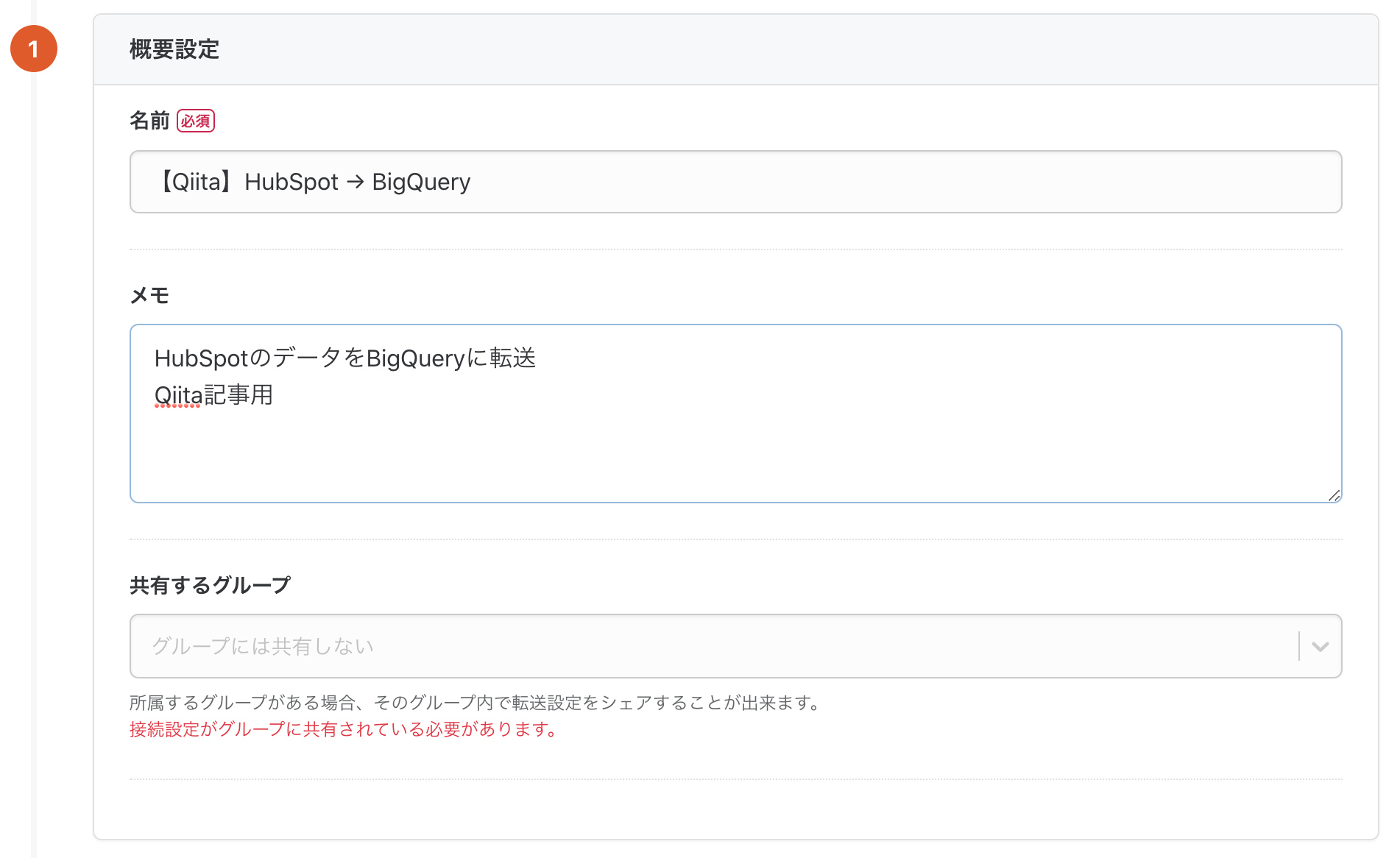
設定画面になるので、必要な情報を入力していきます。
2-2. HubSpotとの連携設定
TROCCO®には社内のユーザー間でチームを作成し、チームで転送設定を共有するチーム機能があります。チームの他メンバーにも転送設定の内容が分かるように名前とメモを入力します。
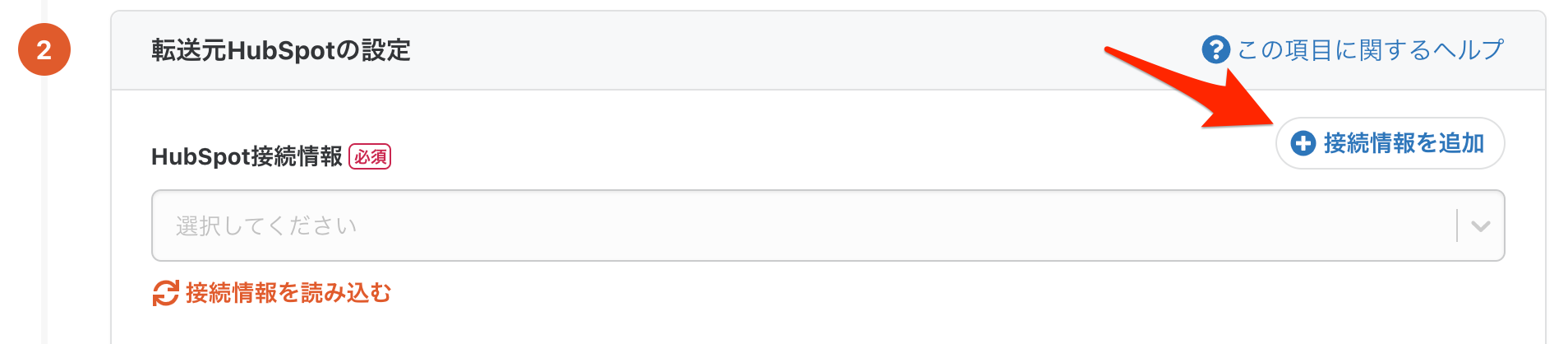
次にHubSpotとの連携に関する設定をするために「転送元の設定」内の「接続情報を追加」ボタンを押します。
別のタブで接続情報の新規作成画面が開きますので、必要事項を記入して保存ボタンを押します。

再度転送設定画面に戻り、接続情報の「再読込」ボタンを押すと、先ほど作成した接続情報が選択できるようになります。

これでHubSpotとの連携は完了です。
2-3. HubSpotからのデータ抽出設定
続いてどのようなデータを取得するかを設定していきます。
取得対象としては、以下のものが設定できます。
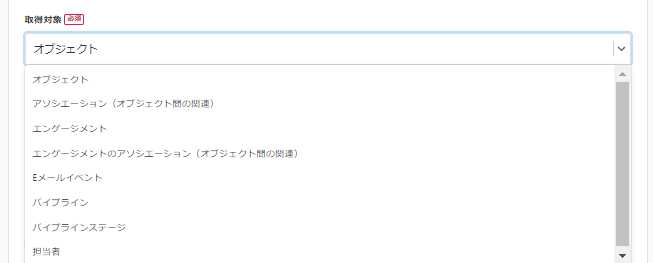
今回は以下の設定でデータを取得します。

2-4. 転送先Google BigQueryの設定
転送元と同じ要領で設定していきます。
「接続情報を追加」ボタンからGoogle BigQueryの接続設定を行います。Googleアカウントとの認証(OAuth)も可能ですがそれを利用しない場合はJSONキーを利用した認証を行います。
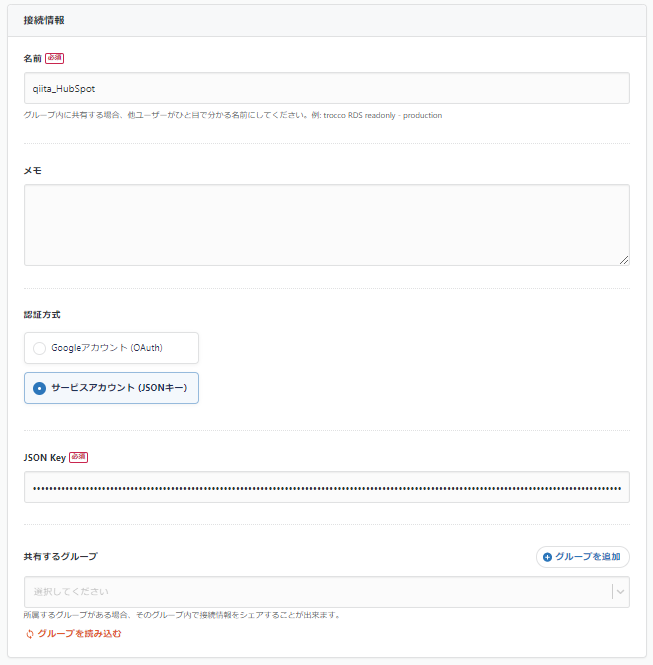
JSONキーの取得方法についてはこちらのドキュメントを参照してください。
「接続情報を追加」ボタンからGoogle BigQueryの接続設定を行い、データベース・テーブル・データセットのロケーションを指定します。

最後に、接続確認が問題なく通るか確認します。

これで入力は完了です。「次のSTEPへ」をクリックして次に進みましょう。
2-5. データのプレビュー
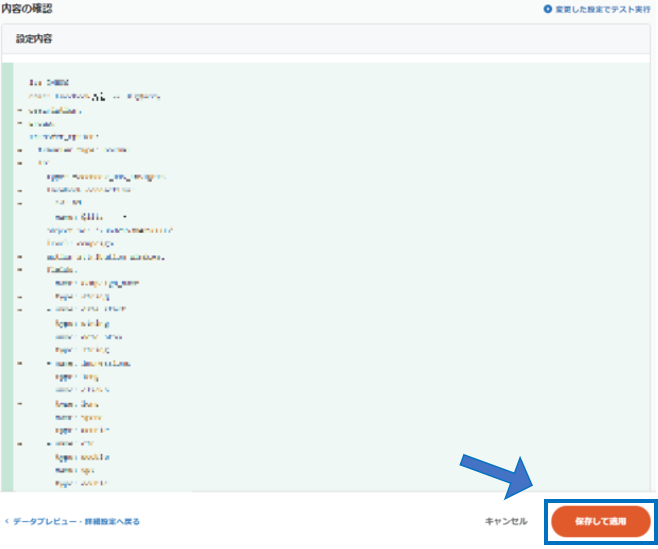
転送設定に従ってHubSpotから転送するデータのプレビューが作成されます。

問題が無ければ確認画面に移り、「保存して適用」を押しましょう。
2-6. スケジュール・通知設定
「スケジュール・トリガー設定」タブを開き、スケジュールを追加します。
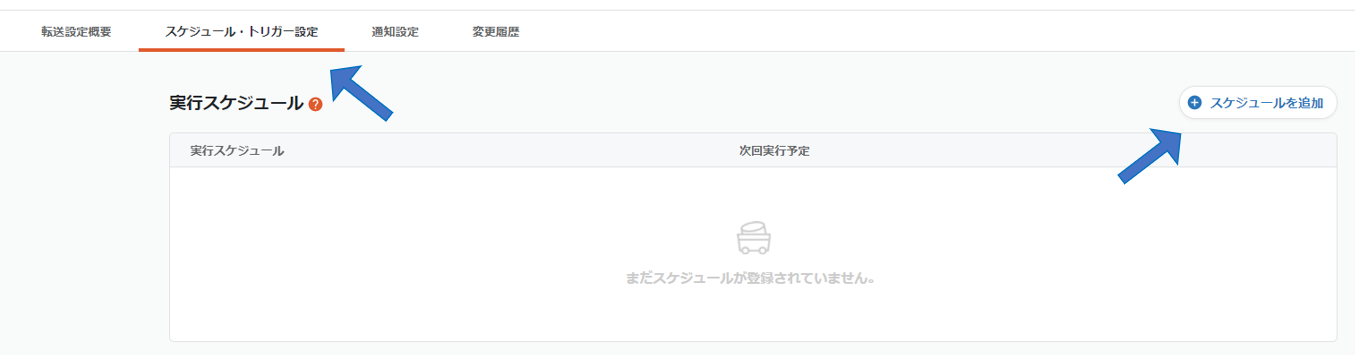
以下のように実行スケジュールを設定することで、転送を定期的に実行し自動化することが出来ます。

また必須の設定ではないですが、ジョブの実行ステータスに応じてEmailやSlackに通知を行うことが出来ます。
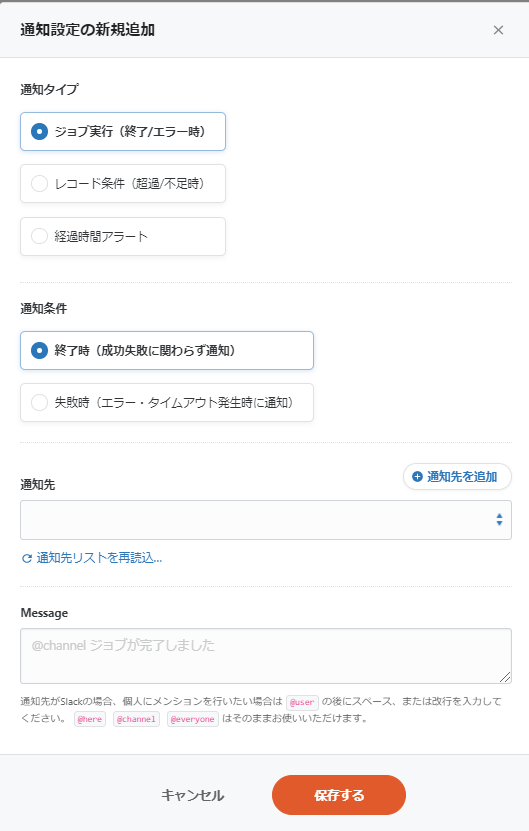
2-7. データ転送ジョブの実行
設定は以上です。最後に、手動で転送ジョブを実行してGoogle BigQueryにデータを送ります。
手動で実行する場合はジョブ詳細画面の「実行」ボタンを押します。

これで転送は完了です。
3. Google BigQueryの設定
Google BigQuery側で特に操作は必要ありません。念の為Google BigQueryのコンソール画面から確認してみるとたしかにデータが転送されていることが確認できます。
転送が成功しているため、今すぐに分析・可視化を行うことが出来ます。
4. Looker Studio(旧:Googleデータポータル)で可視化
Google BigQueryの画面から、「エクスポート > データポータル」を選択します。

すると、以下のようなLooker Studioの画面に遷移します。
今回は各アカウント毎の売上高をグラフにした例を示します。データは私が用意したサンプルを利用します。

以下のようなグラフが出来上がります。
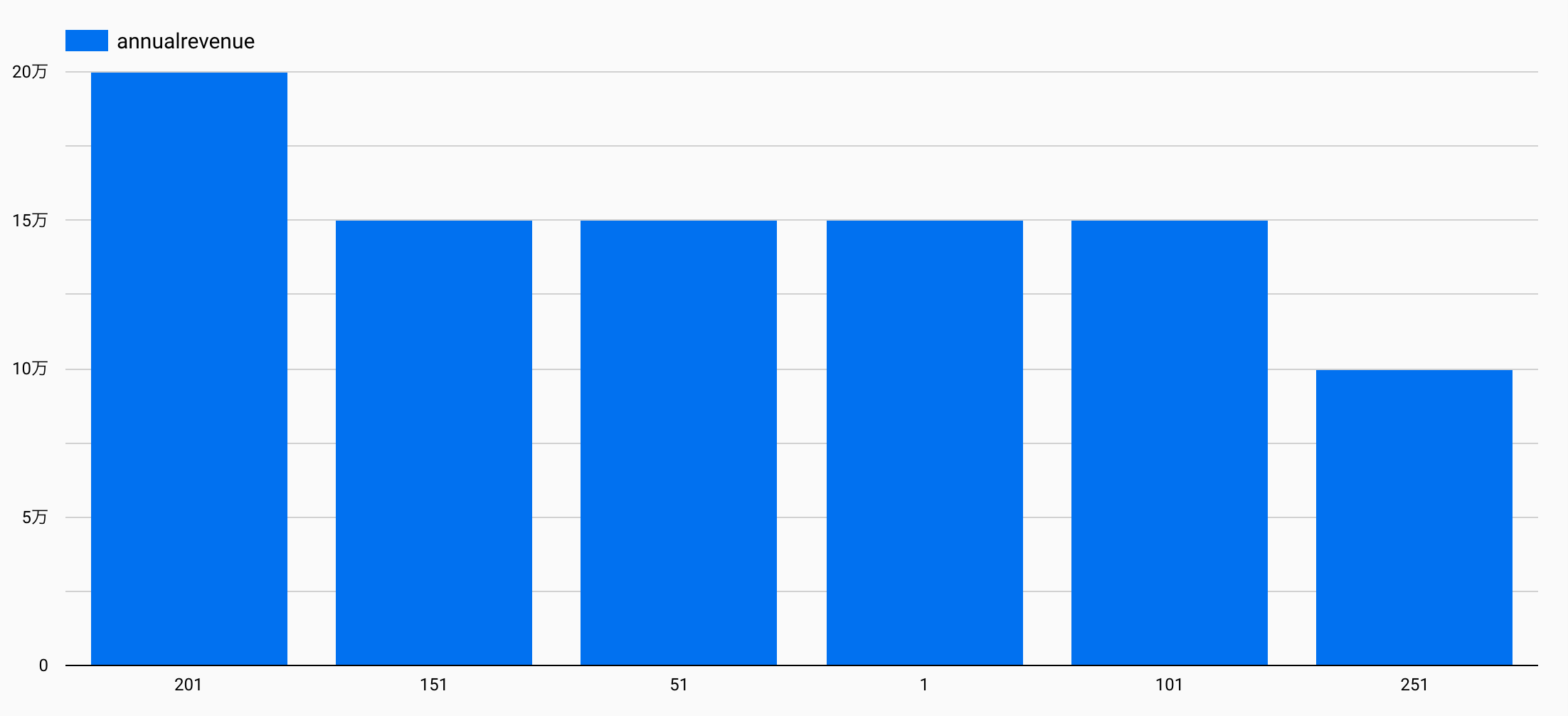
この画面はデータポータルの「エクスプローラ」という機能になります。
データポータルのトップ画面から、「レポート」を作成し、 同様にして他のグラフも作成すると、サービス用ダッシュボードが出来上がります。
まとめ
いかがでしたでしょうか。TROCCO®️を使うとHubSpotの管理画面を触ることなく、簡単にデータを取得し、DWH(Google BigQuery)に統合、連携するLooker Studioでデータの可視化を行えました。
TROCCO®は、ETL/データ転送・データマート生成・ジョブ管理・データガバナンスなどのデータエンジニアリング領域をカバーした、分析基盤構築・運用の支援SaaSです。TROCCO®について詳しく知りたいという方は、以下より資料をご請求ください。
