
こんにちは、小林寛和(@hiro-koba)と申します。私はデータエンジニアのための勉強会「Data Engineering Study」の共同主催者をやったり、ETL & ワークフローサービス「TROCCO®︎(トロッコ)」を運営する株式会社primeNumberの取締役CPOを務めているデータエンジニアです。
データエンジニアの皆さんが普段利用されているDWH/ETL/BIツールに関する最新アップデートや、界隈の最新トピックをまとめて配信しております。
お忙しい方や、サクッと最新情報をキャッチアップしたい方向けに、主要なニュースをピックアップして独自にまとめています。
毎月更新でニュースをお届けしていますので、ニュースの新着メール通知をご希望の方はこちらのフォームよりご登録ください。
Google BigQueryのニュースまとめ
マテリアライズドビューのmax_staleness オプションが利用できるようになりました(Preview)
従来では、マテリアライズドビューは最新のデータを返すという仕様なため、読み取りの度に差分のスキャン量が発生しました。
max_stalenessオプションで間隔を設定すると、最後のリフレッシュが設定以内であれば、ベーステーブルを読み込まずに直接マテリアライズドビューからデータを読み取ります。
最新のデータである必要がないダッシュボードなどから参照されるマテリアライズドビューに対して設定をしておくことで、コストを抑えつつパフォーマンスを最適化することができます。
より詳しく知りたい方は、以下の参考リンクもご覧ください。
Use materialized views with max_staleness option
LOAD DATAステートメントが利用できるようになりました(Preview)
LOAD DATAはファイルをBigQueryのテーブルにロードするSQLのステートメントです。
従来では、GUIやCLI、APIなどからしかファイルのロードが行えませんでしたが、SQLでも行うことができるようになりました。
より詳しく知りたい方は、以下の参考リンクもご覧ください。
LOAD DATA ステートメント
Pub/SubからBigQueryテーブルに直接メッセージを書き込むことができるようになりました。
Cloud Pub/SubでBigQueryのサブスクリプションを設定すると、受信したメッセージをリアルタイムに直接BigQueryテーブルに書き込むことができるようになりました。
BigQuery側のテーブルは存在している必要があります。
Pub/Sub側でAvroやProtocolBufferのスキーマを定義しておくと、BigQuery側のスキーマにマッピングされます。
ただし、スキーマの定義方法がPub/SubとBigQueryで異なるため、互換性のない型に関してはエラーとなります。
Pub/Sub側でスキーマを定義していない場合は、BigQueryテーブルのdataという列に書き込まれます。
より詳しく知りたい方は、以下の参考リンクもご覧ください。
BigQueryのサブスクリプション
その他の変更
- BigLakeの一般提供(GA)が開始されました。
- フォルダ、組織、プロジェクトを予約に割り当てる際に、ジョブタイプを選択できるようになりました。一般提供(GA)となります。
- 逆三角関数SQL関数が一般提供(GA)開始されました。
- 三角関数SQL関数CBRTが一般提供(GA)開始されました。
- AzureワークロードのIDフェデレーションが、BigQuery Omni接続でプレビュー利用できるようになりました。
Amazon Redshiftのニュースまとめ
Redshift Serverlessの一般提供が開始されました
昨年のre:Inventでプレビュー公開されたAmazon Redshift Serverlessが一般提供されました。
Redshift Serverlessでは、Redshiftクラスターのセットアップ等の管理が不要になり、データ分析を簡単に開始できるようになります。
Redshift Serverlessでは、コンピューティングとストレージの料金を個別に支払います。コンピューティング料金はRPU(Redshift Processing Unit)の利用時間に応じて、ストレージ料金はRMS(Redshift Managed Storage)に保存されたデータ量に応じて課金されます。
詳しくは公式ドキュメントを参照ください。
自動マテリアライズドビューの一般提供が開始されました
自動マテリアライズドビュー (AutoMV) の一般提供が開始されました。
ワークロードの変化に対応して有効なマテリアライズドビューを維持するのは大変な作業ですが、AutoMVは、機械学習を使用して現在のワークロードに対して有効なマテリアライズドビューを自動で維持してくれる機能です。
ただし、東京リージョンではまだ利用できないようです。
詳しくは公式ドキュメントを参照ください。
行レベルセキュリティ (RLS) のサポートを開始
行レベルセキュリティ/Row Level Security (RLS) のサポートが開始されました。
RLSポリシーを作成し、ユーザやロールにアタッチすることで、行レベルでのアクセス制御が可能になります。

従来のテーブルレベル/列レベルのアクセス制御とRLSを組み合わせることで、より細かなアクセス制御ができるようです。
詳しくは公式ドキュメントを参照ください。
Snowflakeのニュースまとめ
永続スキーマから一時スキーマへのクローニング機能の動作変更
SnowflakeではTransient(一時的、遷移)テーブルという仕組みがあり、
永続テーブルと違いFail-safe機能を利用しないことで、費用を抑えて利用できるものです。
Transientスキーマや、Transientデータベースという仕組みもあり、そこでテーブルを作成する場合は基本的にはTransientテーブルとなります。※Temporaryテーブルとはまた違うものになります。
これまでは、永続テーブルを一時スキーマへクローニングを実行した際は
永続テーブルとして作成されていました。
今回の変更で、Transientスキーマへクローンする全てのテーブルは
Transientテーブルとして作成されるようになりました。
より詳しく知りたい方は以下の参考リンクも御覧ください。
コマンド・関数・システムビューのアップデート
- SHOW EXTERNAL TABLESコマンドに新しい列情報を追加
SHOW EXTERNAL TABLESはアクセス権限のある外部表の一覧を返すコマンドです。
以下の列が追加されました。- table_format
ステージされたファイルの形式 - last_refresh_details
新機能用のカラム。現在はNULL値のみ。
- table_format
- SHOW SCHEMAS コマンドの RETENTION_TIME 列の返り値の変更
- スキーマのデータの保持期間(Retention time)を0と設定していた場合において
空文字を返していたものが、0と返すようになりました。
- スキーマのデータの保持期間(Retention time)を0と設定していた場合において
- SHOW WAREHOUSES コマンドに新しい列情報を追加
SHOW WAREHOUSESコマンドはアクセス権限があるアカウント内のウェアハウス一覧を返すコマンドです。
Query Acceleration Serviceに関する列情報が追加されました。- enable_query_acceleration
Query Acceleration Serviceが有効かどうかを返す。 - query_acceleration_max_scale_factor
Query Acceleration Serviceの最大倍率。
- enable_query_acceleration
- GET_DDL関数の変更
GET_DDL関数は定義情報を返すコマンドです。
UDF、外部関数、ストアドプロシージャの関数名は
これまでは、ダブルクオートで括られた形で返していたものが、
第3引数にTRUEを加えることで、クオート無しで返す様になりました。
- POLICY_REFERENCESビューに新規列の追加
- 前回の記事で紹介したタグベースによるポリシー設定機能に伴い、POLICY_REFERENCESビューに以下の列が追加されました。
- tag_name
- tag_database
- tag_schema
- policy_status
- 前回の記事で紹介したタグベースによるポリシー設定機能に伴い、POLICY_REFERENCESビューに以下の列が追加されました。
- QUERY_HISTORYビューに新しい列が追加
- QUERY_ACCELERATION_BYTES_SCANNED(NUMBER)
- Query Acceleration Serviceによってスキャンされたバイト数
- QUERY_ACCELERATION_PARTITIONS_SCANNED(NUMBER)
- Query Acceleration Serviceによってスキャンされたパーティションの数
- QUERY_ACCELERATION_UPPER_LIMIT_SCALE_FACTOR(NUMBER)
- Query Acceleration Serviceによって得られる高速化倍率の最大倍率。
- QUERY_ACCELERATION_BYTES_SCANNED(NUMBER)
- ALTER STREAM コマンドの変更: APPEND_ONLY、INSERT_ONLYパラメタ変更が不可に
- stream作成時に以下のオプションを設定しますが、今後は変更はできなくなるとのことです。
- APPEND_ONLY: trueの場合、一般テーブル、ビューのstreamとしてのみ利用する。
- INSERT_ONLY: trueの場合、外部表のみのstreamとして利用する。それ以外は利用できない。
- 既存のstreamに対して変更を加えたい場合は、
CREATE OR REPLACE STREAMを実施し
streamの再作成をすることで対処できるようです。
- stream作成時に以下のオプションを設定しますが、今後は変更はできなくなるとのことです。
より詳しく知りたい方は以下の参考リンクも御覧ください。
Lookerのニュースまとめ
Google Maps Visualization (Labs) が追加
Google Map 上で地理データの可視化を行えるようになりました。
詳しくは「[Looker22.12新機能]Google Mapsをバックグラウンドに用いた可視化が出来るようになりました #looker | DevelopersIO」をご覧ください。
リリースノート: https://docs.looker.com/relnotes
Looker User Meetup Online #8 が開催されました
2022年7月21日に、Looker User Meetup Online #8が開催されました。Lookerを活用されている、Unipos株式会社、BASE 株式会社、株式会社タイミー、株式会社フィードフォースの4社から発表が行われました。
見逃した方は、ぜひ発表スライドを是非ご覧ください。
Googleデータポータルのニュースまとめ
データコントロールにてGoogle Analytics4をプロパティとして使用可能になりました
データコントロールとは、レポート閲覧者側で特定のデータソースで使用されるデータセットを変更できる機能となります。
データコントロールを使用することができるデータソースは下記のようになります
- Google Analytics (Universal Analytics and Google Analytics 4)
- Google Ads
- Attribution 360 (TV Attribution)
- Google Ad Manager
- Campaign Manager 360
- Search Console
- YouTube
今回のリリースでGoogle Analytics 4もデータコントロールで使用可能となりました。
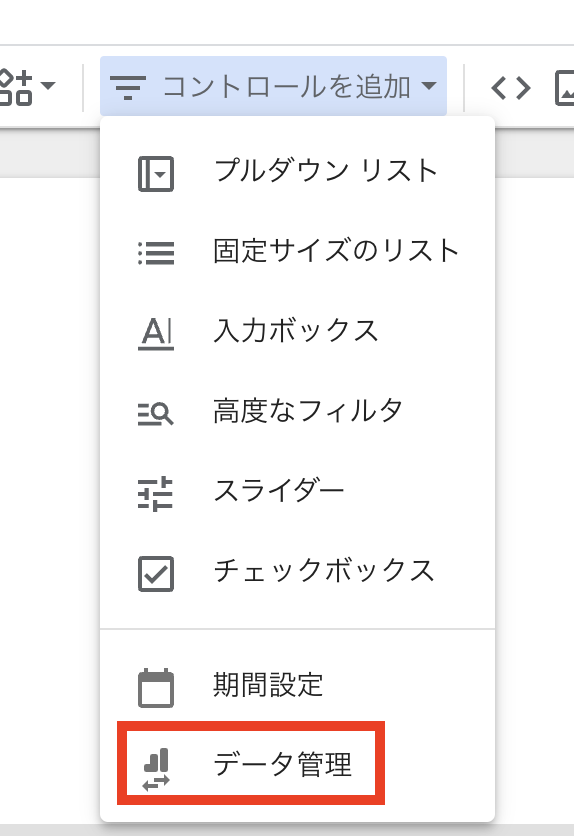
データコントロールは下記の手順で設定することができます。
- レポートを編集します
- ツールバーでコントロールを追加選択します
- コントロールタイプの中からデータ管理を選択し、適切な場所に配置します
- 右側のプロパティパネルのオプションから下記のように設定してコントロールを構成します
- コネクタの種類: Google アナリティクス
- Data set type: Google Analytics 4

データコントロールについて詳しく知りたい方はData controlをご覧ください。
その他のデータポータルのリリース情報を詳しく知りたい方はリリースノートをご覧ください。
dbt のニュースまとめ
dbt-core v1.2.0 がリリースされました。
設定に grants が追加されました
権限管理のために、config で使用できる grants が使用できるようになりました。
標準の Materializationと、有名なアダプターで使用できます。
v1.2 以前において権限設定をする場合は hooks を定義していましたが、より簡単に記述できるようになりました。
-- v1.2
{{ config(
materialized = 'incremental',
grants = {'select': ['reporter']}
) }}
-- v1.2 以前
{{ config(
materialized = 'incremental',
post_hook = ["grant select on {{ this }} to reporter"]
) }}詳細は公式Docsをご確認ください。
grants | dbt Docs
expression 型のメトリクスが使用可能になりました
expression 型のメトリクス(Metrics) が定義できるようになりました。
また、metric() 関数が追加され、モデル、マクロ、expression 型メトリクスでこの関数は使用できます。
expression 型のメトリクスで、metric() 関数を使うことで他の Metrics を参照した計算を記述できるようになります。
type: expression
sql: "{{metric('total_revenue')}} / {{metric('count_of_customers')}}"詳細は公式Docsをご確認ください
Upgrading to v1.2 (latest) | dbt Docs
ETLサービス「TROCCO(トロッコ)」のニュースまとめ
TROCCOの直近のアップデートをご紹介します。
データカタログ
テーブル情報
カラムベースのデータリネージ機能
データカタログ機能にて、カラムベースのデータリネージが自動生成されるようになりました。
データリネージを参照することで、分析で利用予定のカラムがどのカラムのデータを元に作られたのかといった関係性を調べることができます。
基本メタデータの追加
テーブル情報/カラム情報タブで基本メタデータを定義できるようになりました。
それぞれのテーブルについて「論理名」「説明」を定義できます。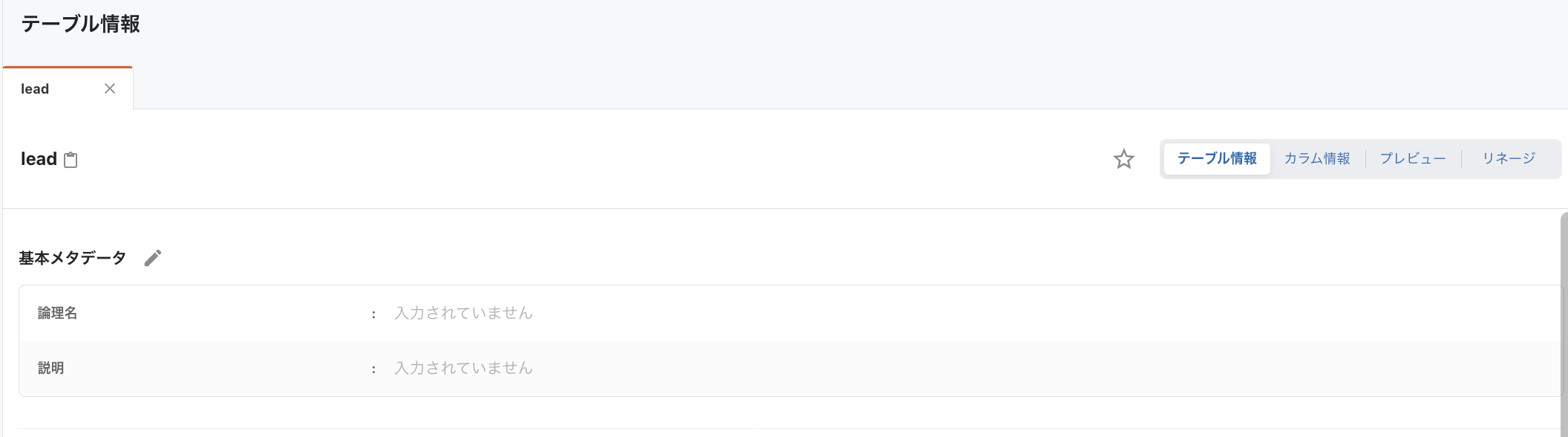
定義した論理名はテーブル一覧や検索結果画面で表示されるため、ひと目で何のテーブルか確認することができるようになります。
カラム情報画面に、複数のユーザ定義メタデータを表示できるように
お客様自身で定義したメタデータを、各テーブルのカラム一覧上で閲覧することができるようになりました。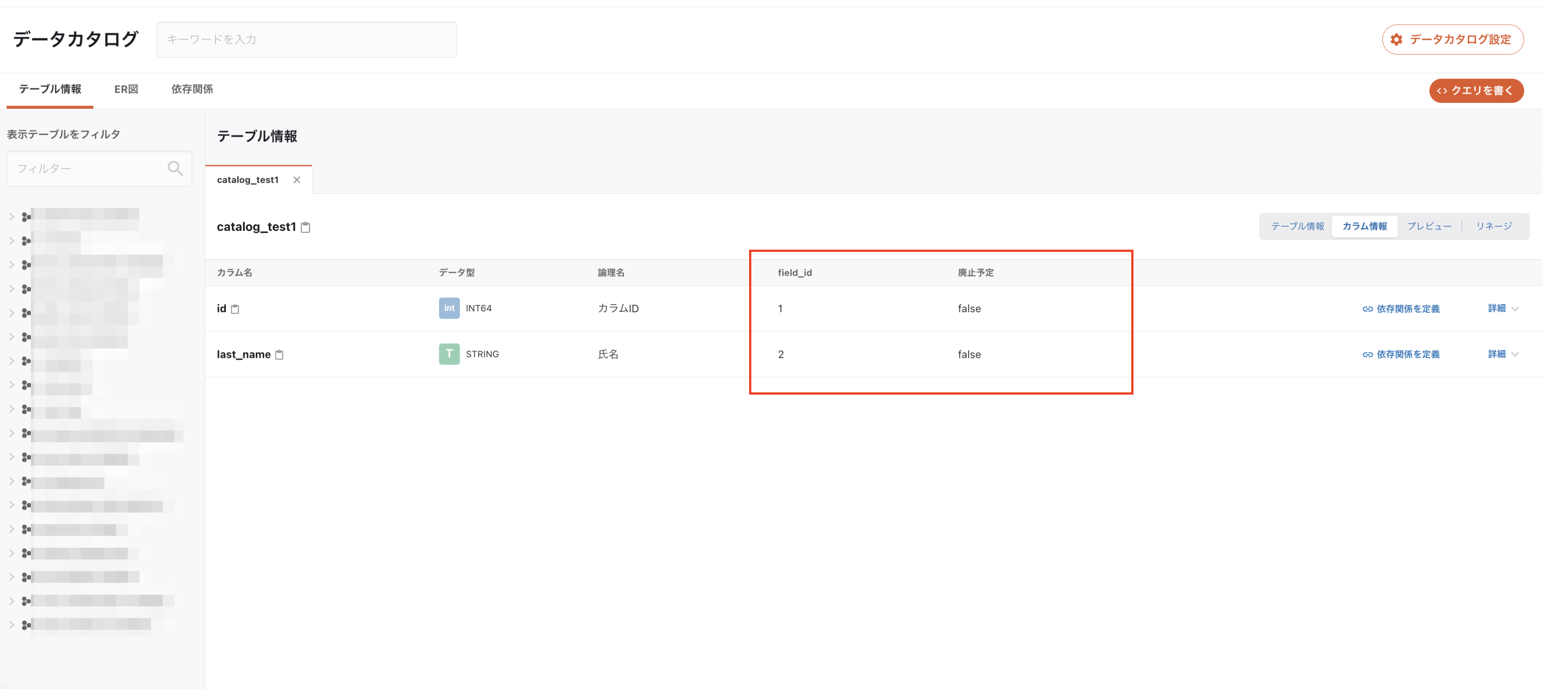
上記設定は「ユーザー定義メタデータ用テンプレート」から設定することが可能となっております。
お気に入り機能の追加
テーブルの「お気に入り」機能が実装されました。
星アイコンをクリックすることでお気に入り追加・削除を設定できます。
お気に入り登録したテーブルはテーブル一覧で一番上に表示されます。
転送設定
転送先 Google Drive が追加 🎉

お客様にてご利用いただいている Google Drive のフォルダに、csv ファイルなどを転送することが可能となります。
ご利用にあたって必要な情報は以下をご覧ください。
転送元 Marketo にて、プログラムメンバーが取得できるように
Marketo 上で設定・実行している各種施策の対象者(プログラムメンバー)の取得が可能となります。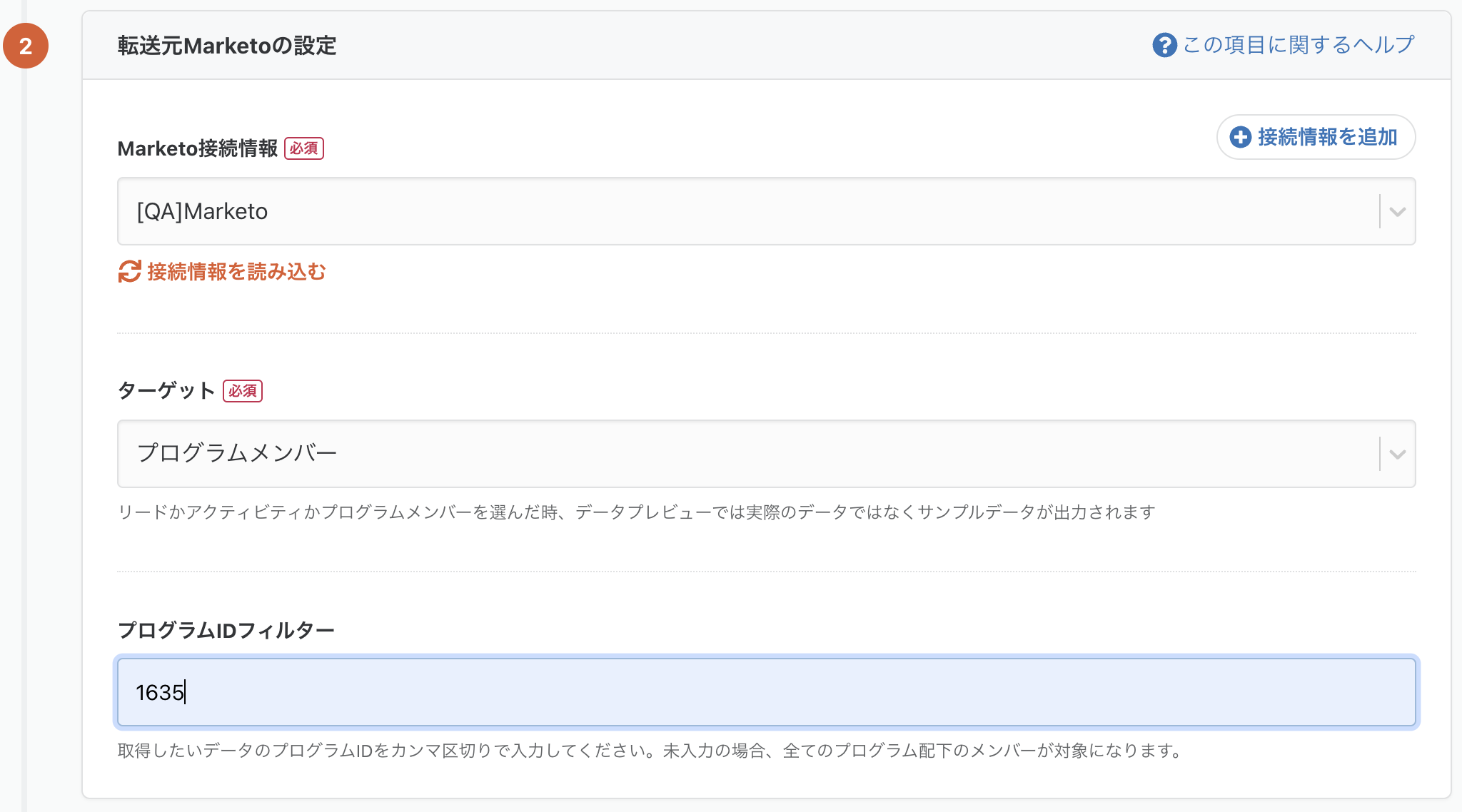
転送元 Marketo にて、スタティック別リードを取得する際、リスト ID で絞り込み(フィルタ)ができるように
Marketo 上で分類しているリストごとのリード取得が可能となります。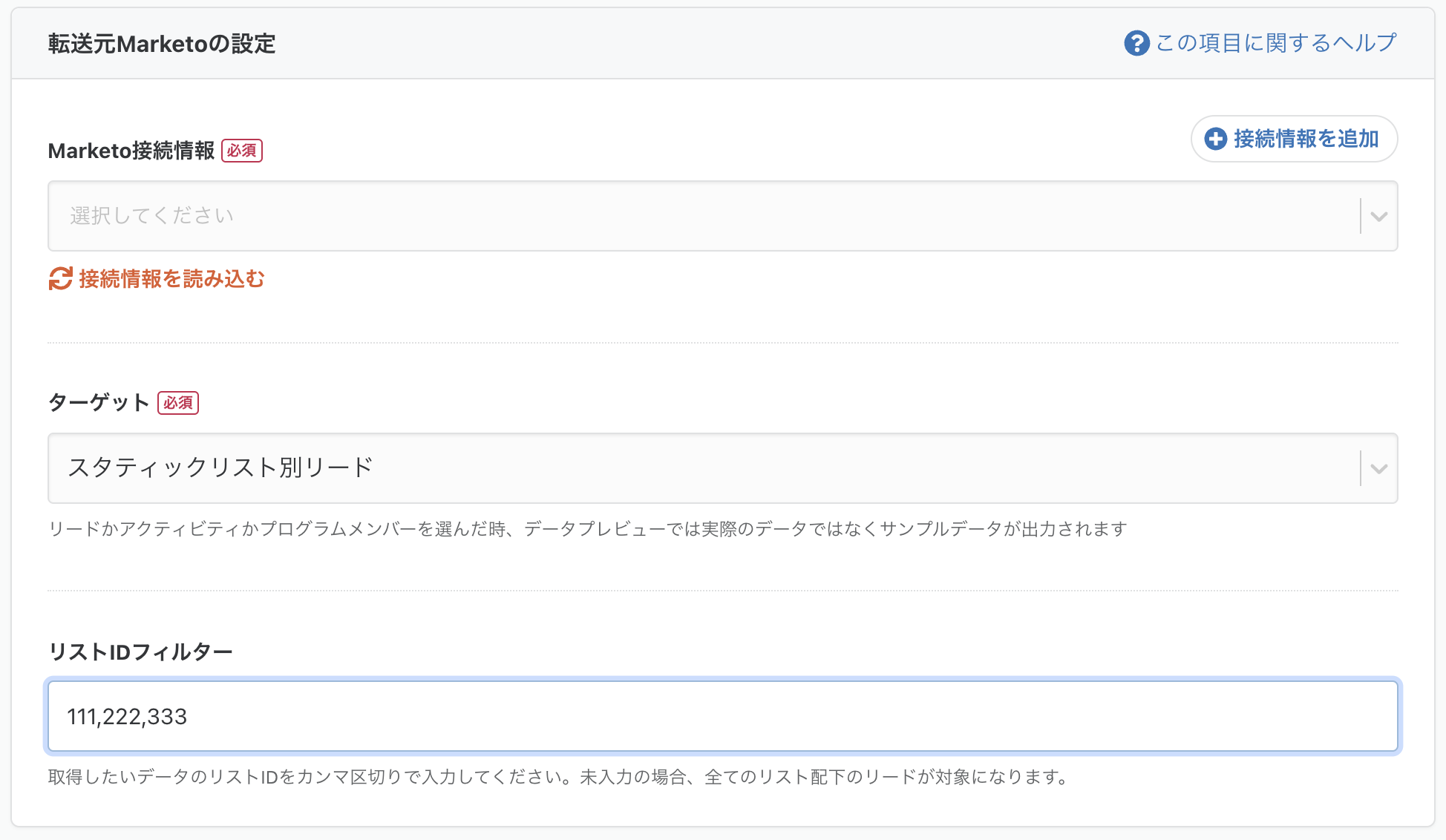
転送元 Salesforce が OAuth 認証に対応
これまでは ID/PW での認証のみに対応していましたが、この度、OAuth 認証で作成した Salesforce 接続情報を利用できるようになりました。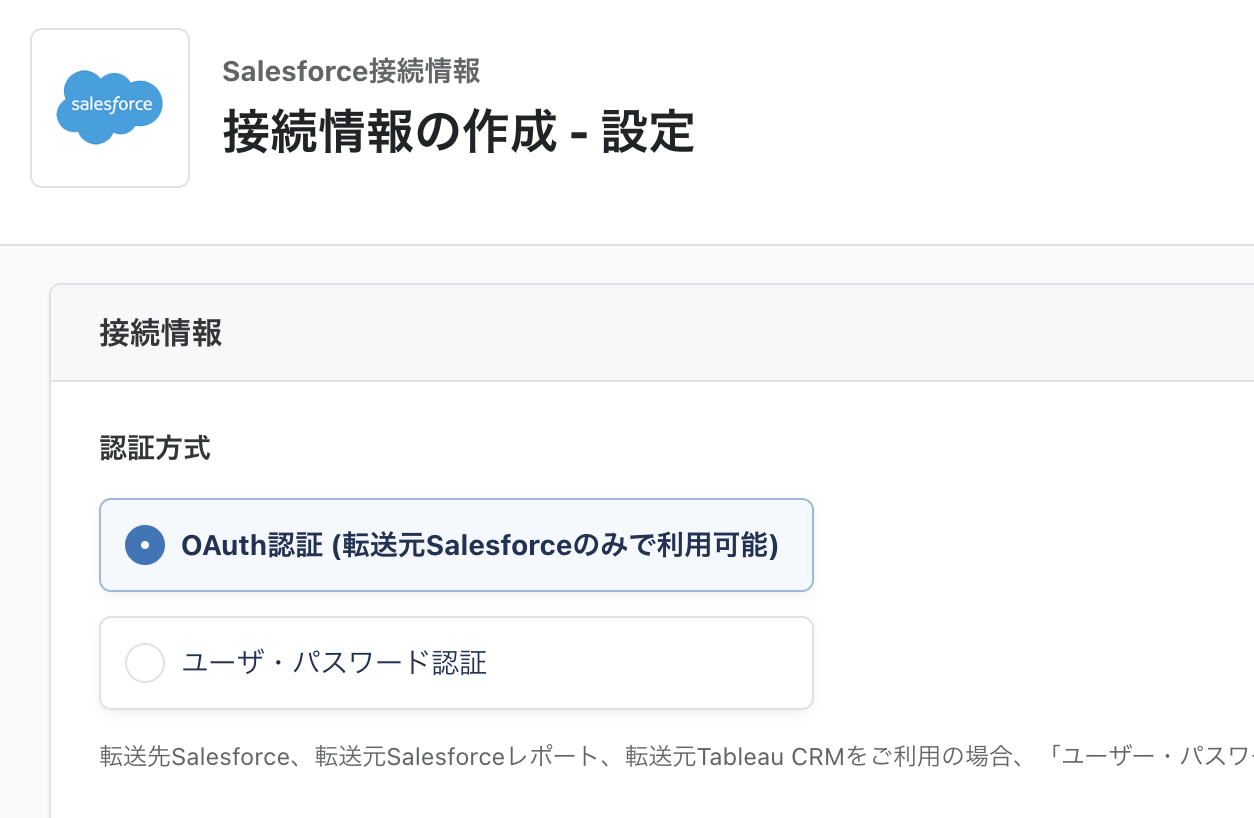
なお、転送先 Salesforce、転送元 Salesforce レポート、転送元 Tableau CRM はリリース時点では OAuth 認証に未対応です。
詳しくは、以下ヘルプページをご覧ください。
https://documents.trocco.io/docs/connection-configuration-salesforce
転送元 Shopify にて、transaction オブジェクトが取得できるように
Shopify 上で保持している、order に紐づく金銭取引データ(トランザクションデータ)を取得可能になりました。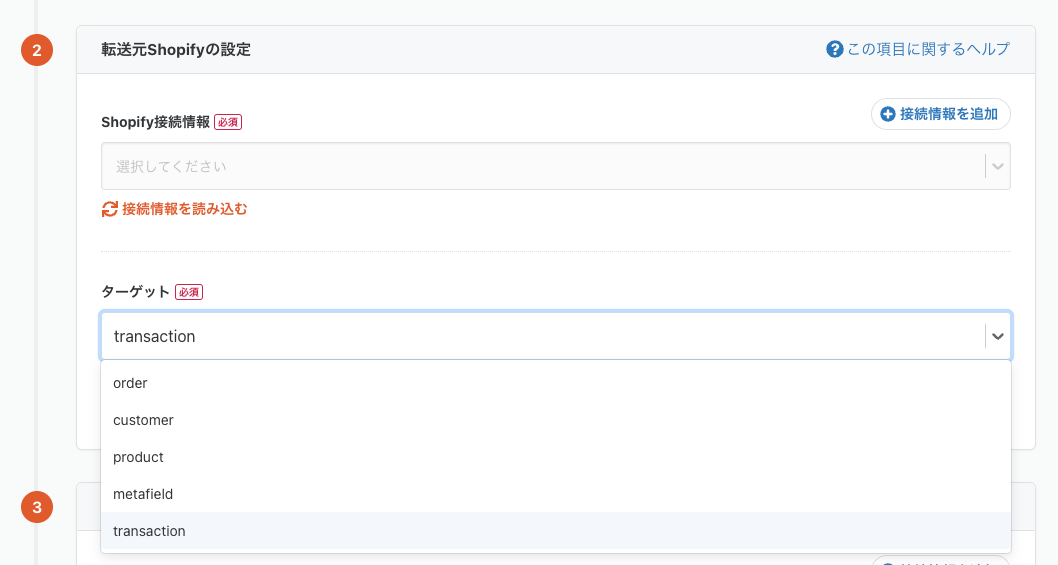
その他データと組み合わせることで、より高度に Shopify 上のデータを分析することができます。
ワークフロー
ワークフロージョブの自動リトライ機能が追加
ワークフローが失敗した際に、自動リトライが行えるようになりました。
ワークフロー全体設定画面より、自動リトライ回数を設定することができます。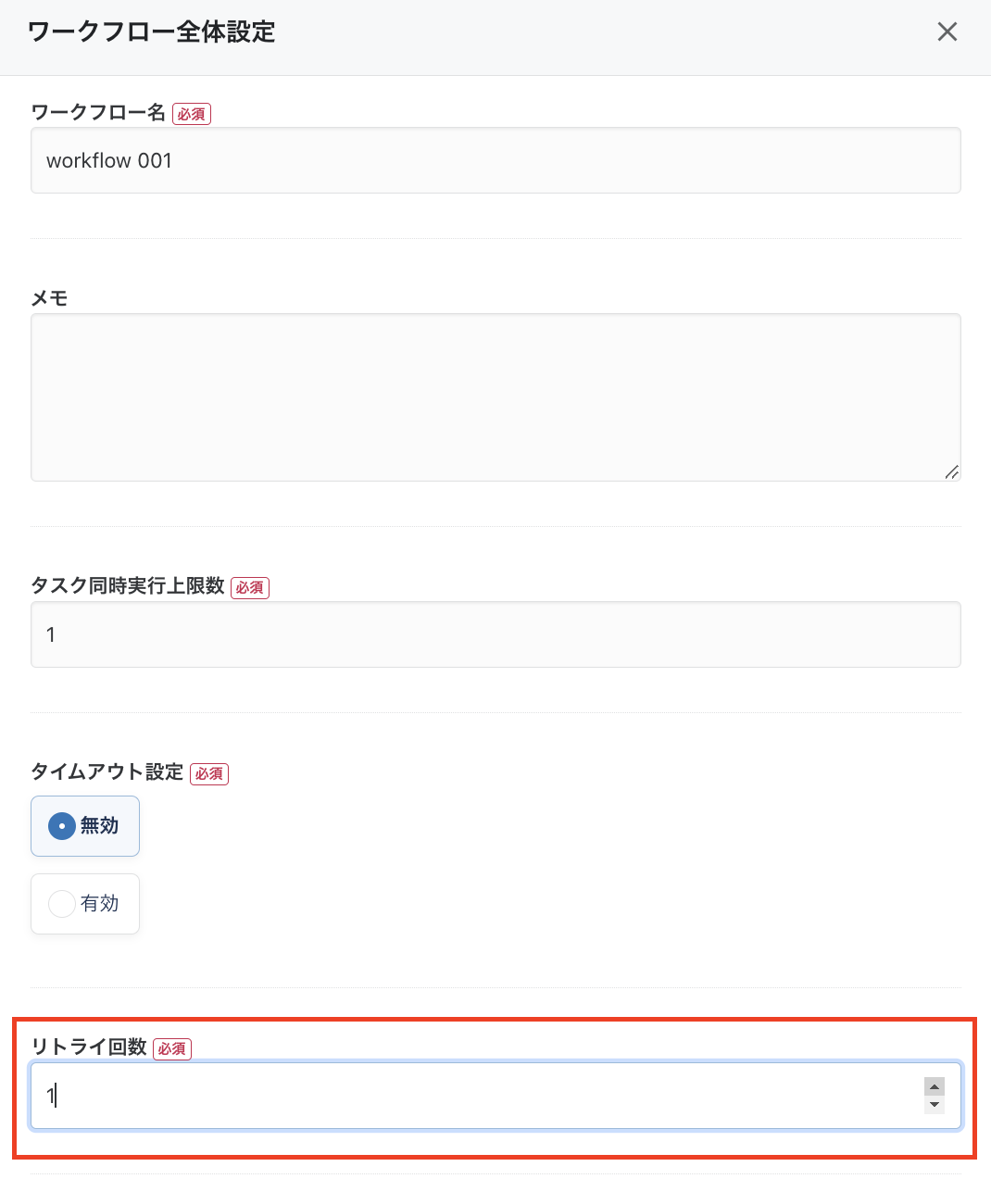
ワークフロージョブ上で実行される子や孫のワークフロージョブが途中で停止した場合、停止位置から再実行できるように
今までのワークフローでは、親のワークフロージョブを再実行した際、子や孫のワークフロージョブは最初から実行される仕様となっており、
子や孫のワークフロージョブが途中まで成功していた際に使いにづらいものとなっておりました。
今回のアップデートで、子や孫のワークフロージョブについても、親ワークフロージョブと同様に、途中から実行されるようになりました。
その他、詳しいアップデートは以下リリースノートをご参照下さい。
https://documents.trocco.io/docs/release-note-2022-07
以上、Data Engineering News 2022年7月のアップデートまとめでした。
毎月更新でニュースをお届けしておりますので、ニュースの新着メール通知をご希望の方はこちらのフォームよりご登録ください。
こんなニュースを知りたい!というようなご意見・ご要望も著者Twitterアカウントまでお気軽にDM下さい!