
はじめまして。ゆずたそ(@yuzutas0)と申します。
株式会社primeNumberのデータ分析基盤向け総合支援サービス「TROCCO®️」(トロッコ)を提供いただくことになったので、レビューしていきたいと思います。まずは簡単に試してみて「実際のところ TROCCO ってどうなの?」をお伝えします。
※ この「TROCCO体験記」は全4回の連載となります。
- 第1回:トライアル編(本記事)
- 第2回:使ってみた感想
- 第3回:利用事例リサーチ
- 第4回:運営者ぶっちゃけQ&A
はじめに
今回はトライアル編です。とりあえず1回試しましょう。以下のシステム構成を実現します。
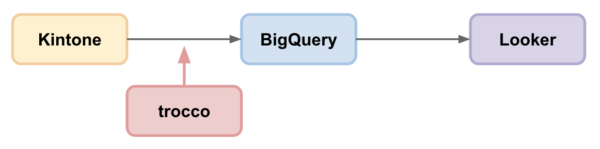
- kintone:営業活動に伴うデータの入力
- BigQuery:分析用データベース(データウェアハウス)
- ooker:データを可視化するダッシュボードツール
以前 DLG Cross というイベントで「データマネジメントなき経営は、破綻する」という講演を行ったところ、とある企業様から「法人営業部のDX(デジタルトランスフォーメーション)を手伝ってほしい」と相談を受け、業務フローの見直しやデータ整備を支援しています。
営業データはこれまで十分に使えていなかったため、新規のデータ連携になります。同社のソフトウェアエンジニア(A氏)に社内調整を進めていただきました。本番データにいきなりアクセスするのは怖いので、トライアル的に行いましょうという会話になりました。
なお、今回の作業を進めるに当たって、primeNumberのCPOである小林さん(@hiro_koba_jp)とembulk-input-kintone開発者である@giwaさんにサポートいただきました。
kintoneの準備
TROCCOの画面を開く前に、kintoneでダミーAppを作成しておきます。このような表形式でデータを格納しています。
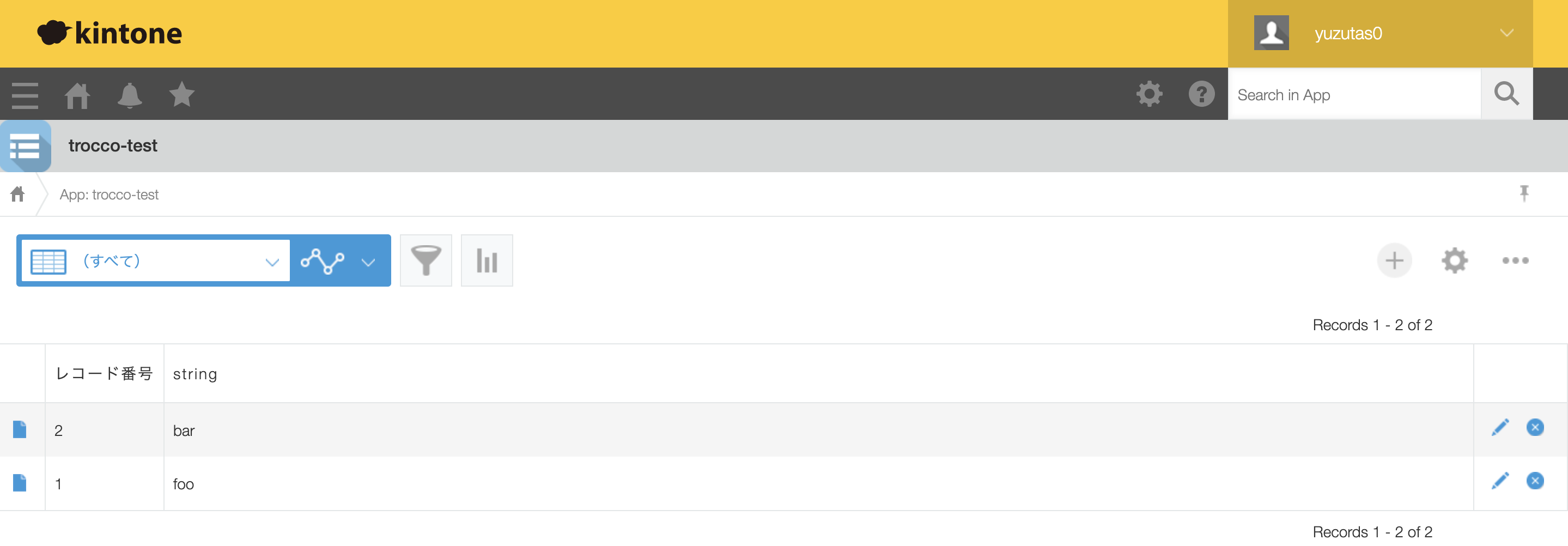
右上の歯車アイコン >「Form」タブ> 項目名 >「Settings」とボタンを押し進めて、入力項目の詳細設定を確認します。
この「Field Code」がデータ取得のカラム名に相当します。日本語カラムでBigQueryにデータを流すと表示がおかしくなるので、アルファベット文字列で設定しておきましょう。

STEP1: 転送元・転送先の設定
前準備ができたので、TROCCOにログインします。一般的なメールアドレスとパスワードでの登録・ログインになっています。

データ転送設定ジョブは、3つのSTEPで作成するようです。また、接続元のIPアドレスも明示されているので、必要に応じて穴開けを行いましょう。
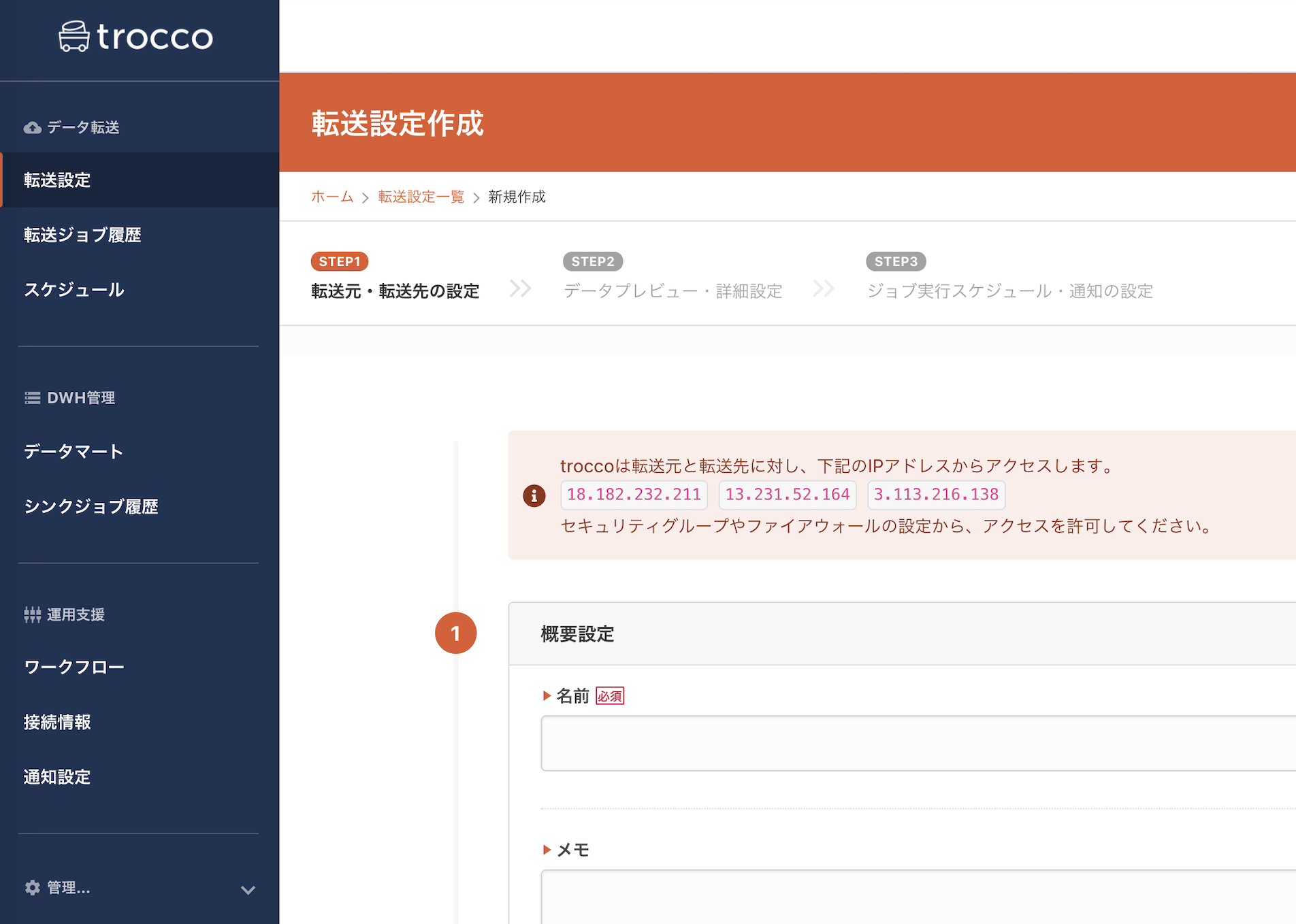
転送設定(ジョブ)の名前と説明文を記入します。kintoneの営業データを分析者向けのBigQueryに転送するサンプルなので「sample-sales-kintone-to-analyst-bigquery」と設定しました。ただ、この命名規則ではジョブが増えると管理しにくいように思います。工夫の余地がありそうです。
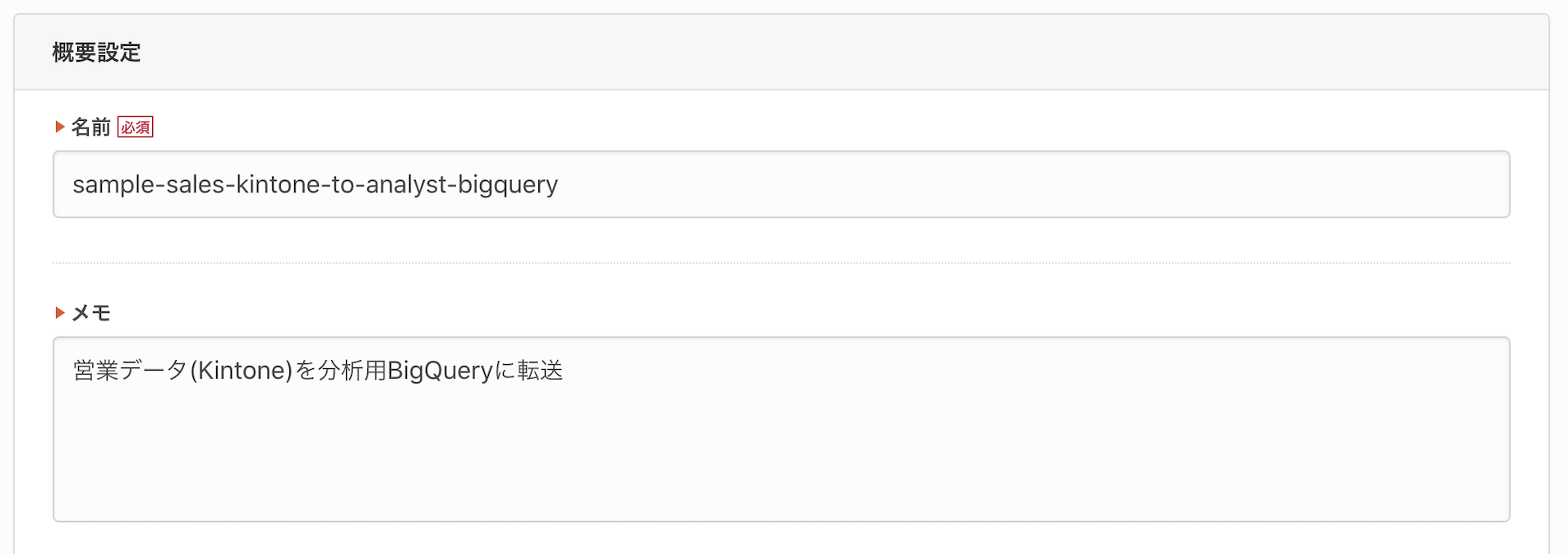
STEP1では転送元・転送先の設定を行います。

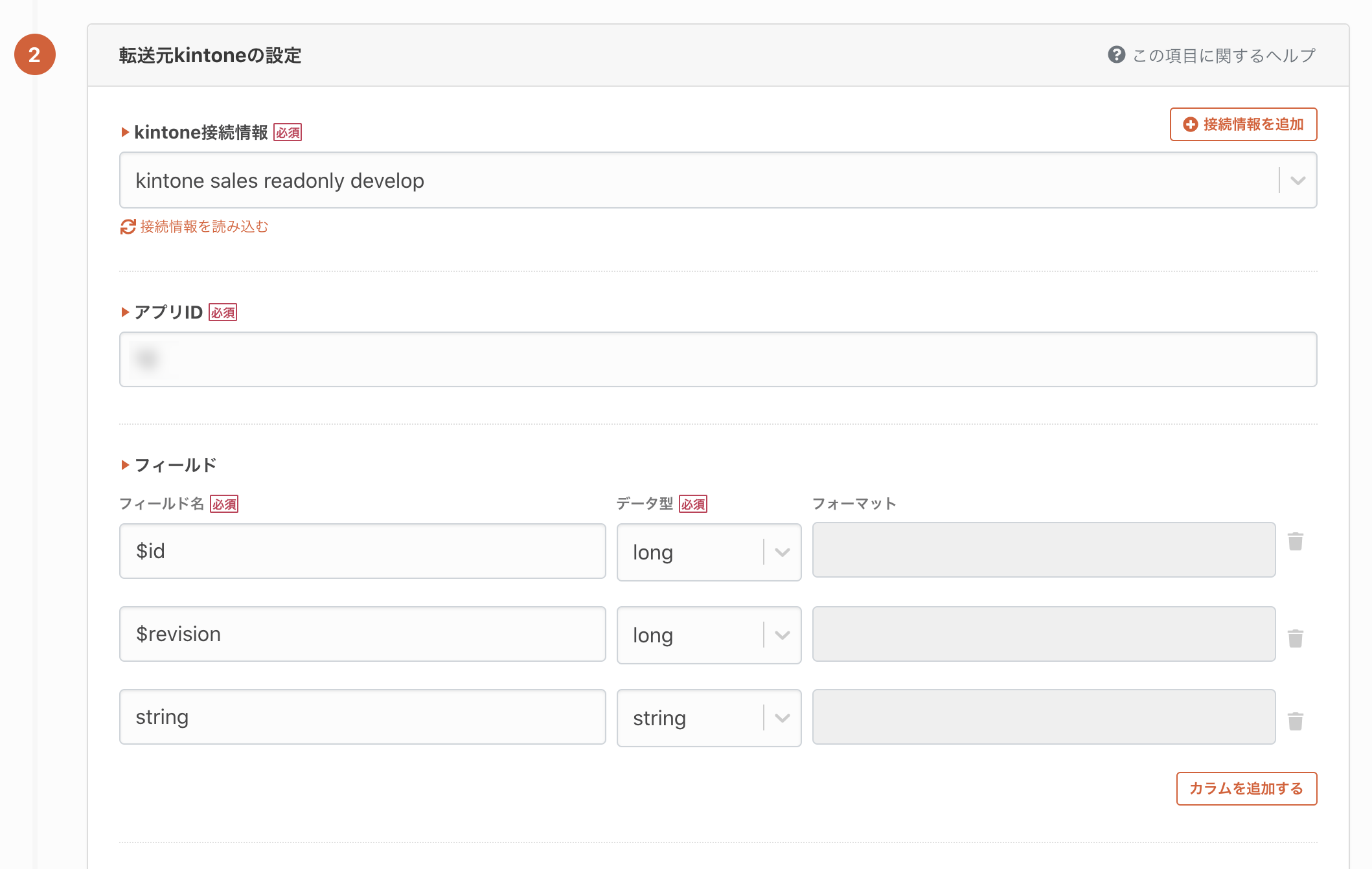
転送元の候補です。今回は転送元にkintoneを指定します。

kintoneの接続先URLや接続認証を行います。ユーザーID・パスワードとAPIトークンの両方に対応しています。kintoneの接続設定についてはこのページに説明があります。

kintoneのアプリや取得データを設定します。kintoneの画面に記載されていないメタデータ(idや更新日時など)は、Cybouzuの開発者向けサイトに記載があります。
転送先も同様に選択します。今回はBigQueryを設定します。

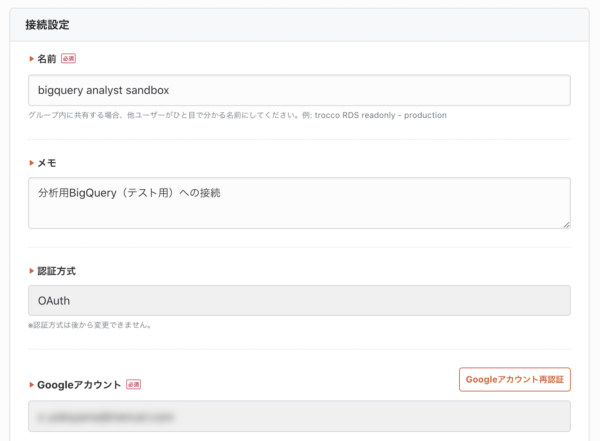
BigQueryに接続するためのアカウント認証を行います。本番環境で使う場合は、担当者の異動・退職で道連れにならないように、サービスアカウントを発行してJSONキーを入力しましょう。

BigQueryへの接続設定が作成されました。名前や説明文を書いておきます。
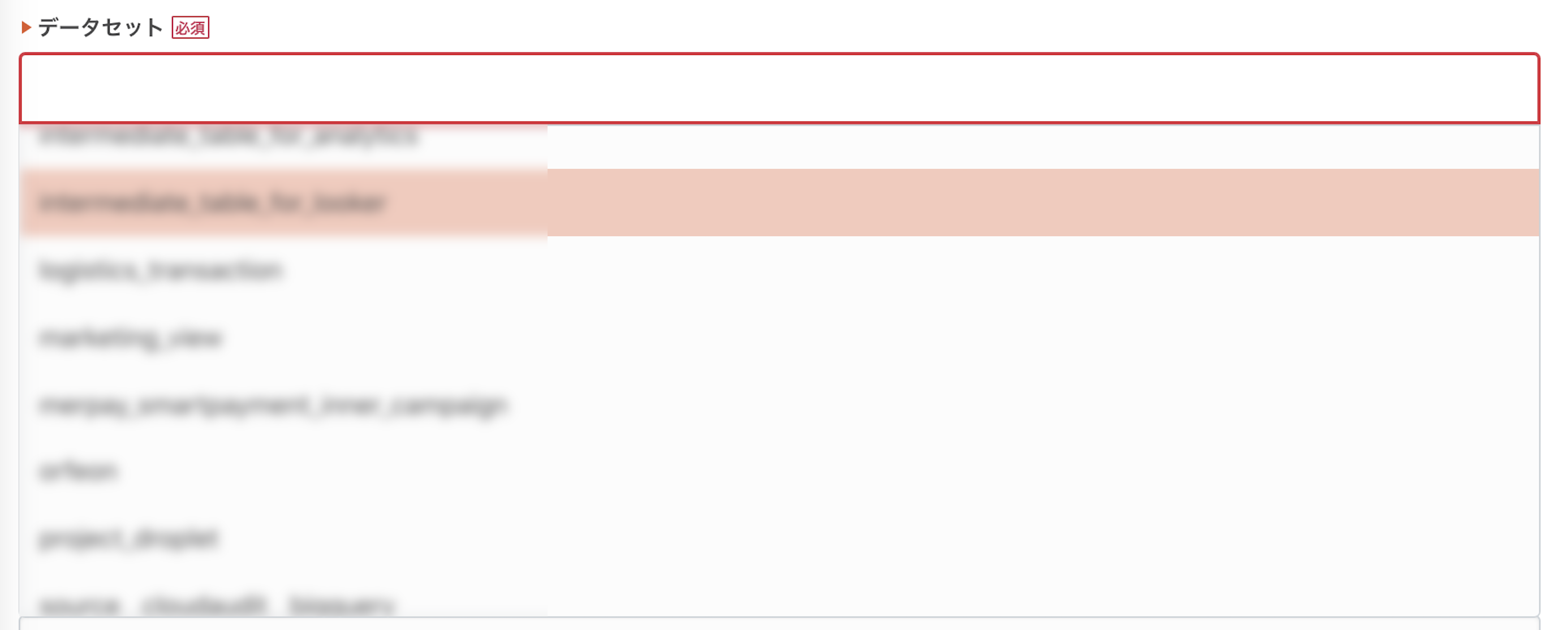
BigQueryのどのデータセット・テーブルに保存するか選択します。YYYYMMDDなどのテーブル名を変数で動的に付けられるので、パーティション機能もばっちり使えますね。

自動で候補を提示してくれます。ささやかですが、使いやすいなと感じました。
転送元と転送先を指定したらSTEP1は終了です。

STEP2: データプレビュー・詳細設定
STEP2は、サンプルデータのプレビューを確認し、必要に応じてデータの入出力について詳細設定を行います。kintoneのデータは無事に取得できているようです。
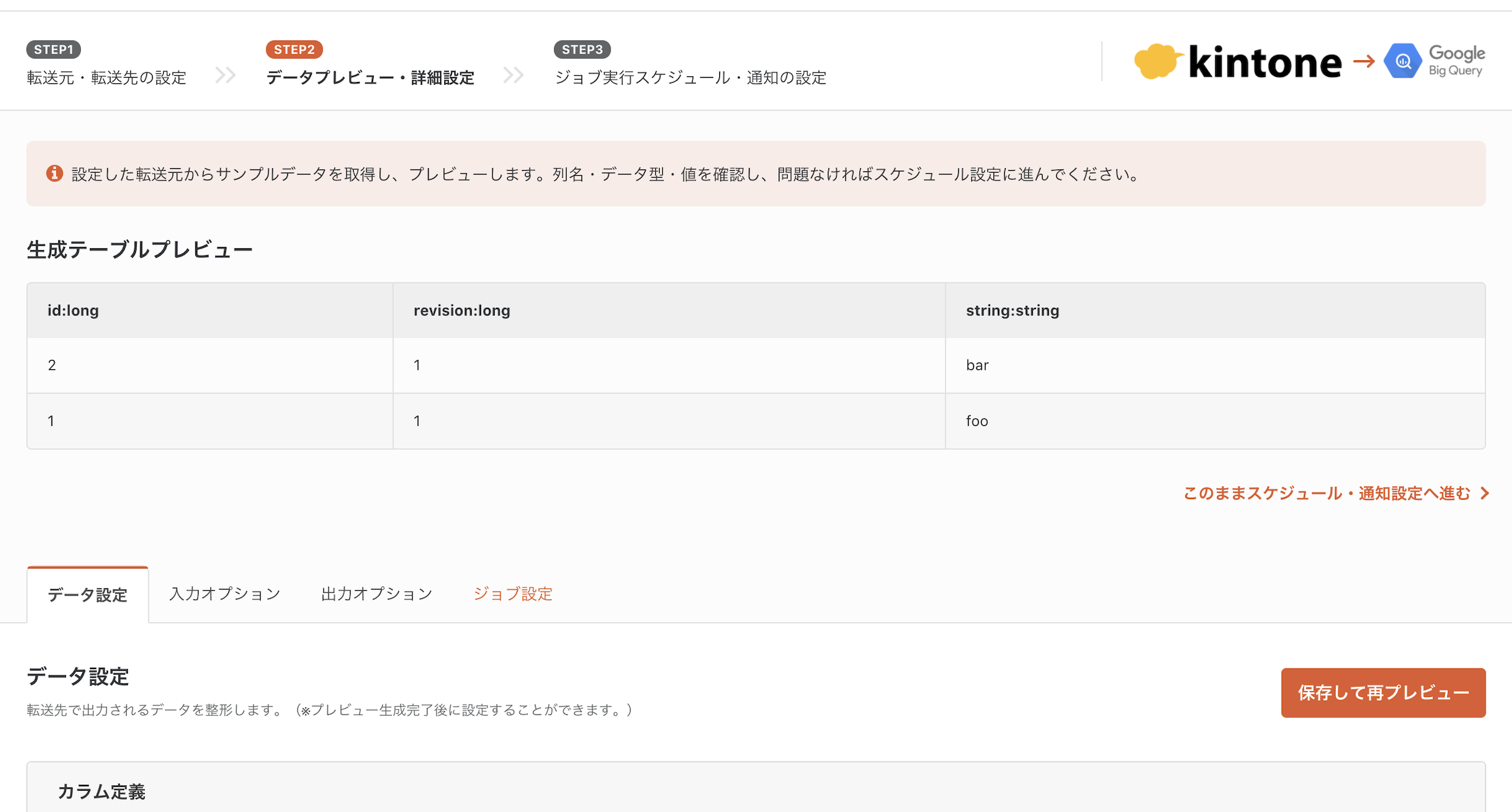
マスキング機能があるようです。セキュリティ観点で保護すべきカラムを指定すると「*」に置き換えてデータを連携します。
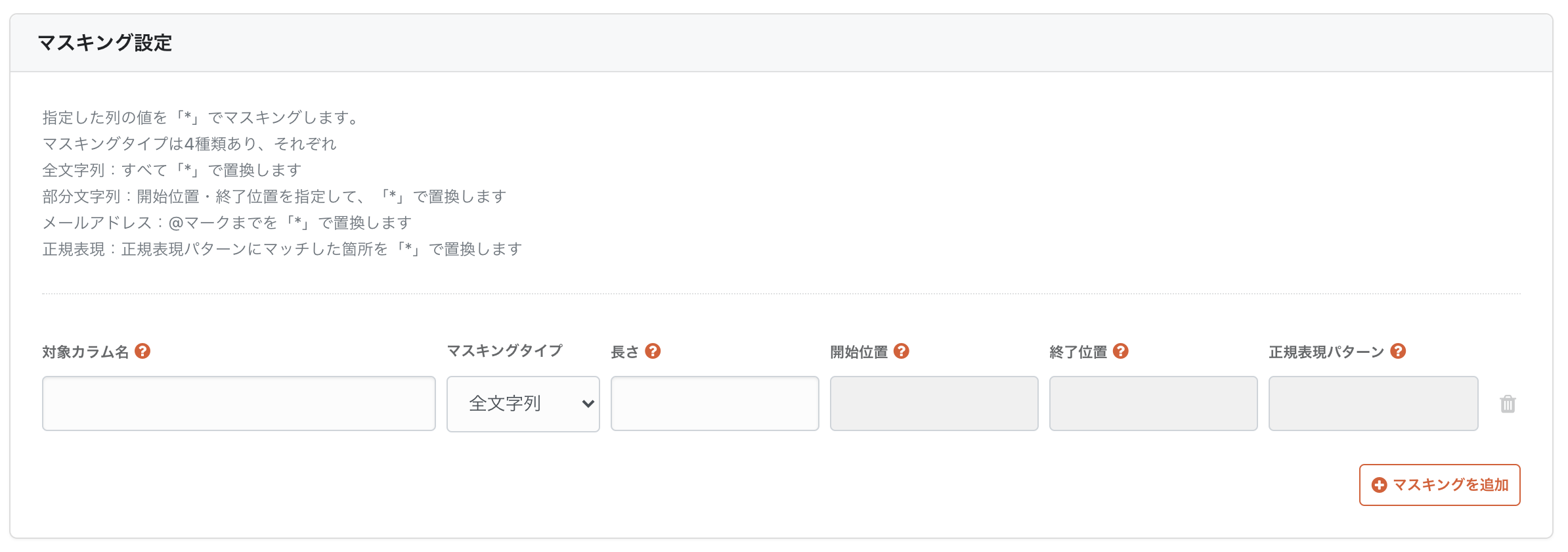
「*」に置き換える代わりに、ハッシュ化で済ませることも可能です。
例えば、メールアドレスを暗号化すると、匿名性を保ったまま、同じメールアドレスによる重複登録を分析することができます。Google広告の顧客データ管理でも採用されている方法ですが、念のため所属会社のセキュリティ担当に相談するのが良いかと思います。
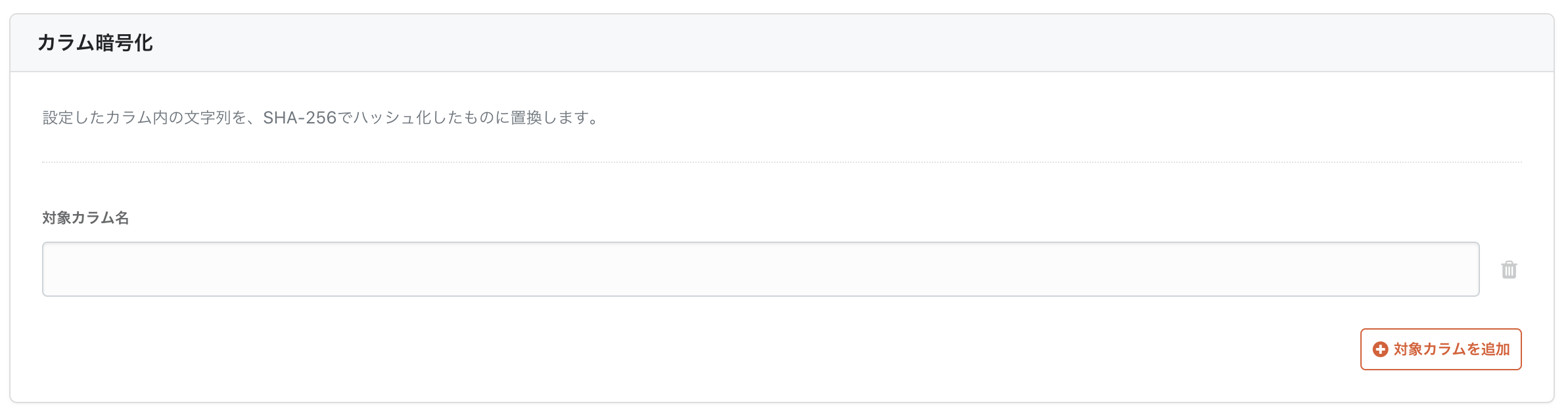
転送時刻をカラムに追加することも可能です。障害対応や差分更新、パフォーマンス改善に役立ちます。私個人としては、転送時刻(メタデータ)を書き込むよりも、ER設計の見直しやワークフローエンジンの利用を検討するほうが筋が良いと考えていますが、業界ではよく使われる方法ではあります。

BigQueryの場合、取り込み時間でテーブルを分割する方法だけでなく、特定カラムの日付・タイムプタンプを参照してテーブルを分割することもできます。

STEP3: ジョブ実行スケジュール・通知の設定
STEP3はジョブ実行と通知の設定です。

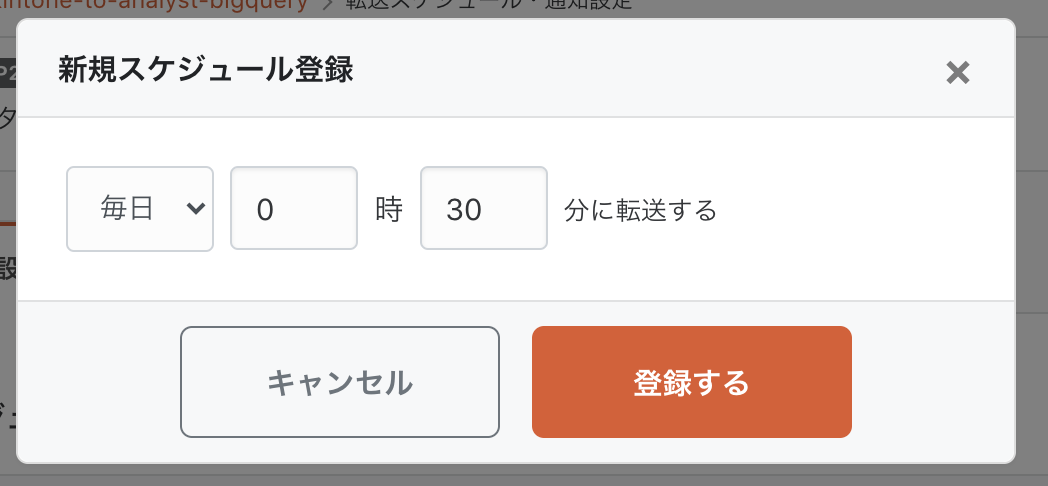
実行スケジュールの設定画面です。毎週の指標集計、毎日深夜のログ転送、毎時の差分取り込みなど、代表的なユースケースは対応できる作りになっています。
他のデータ転送ジョブを実行トリガーとして設定することもできます。ジョブAが成功したらジョブBを実行する、といった形で段階的にジョブを実行できるとのことです。
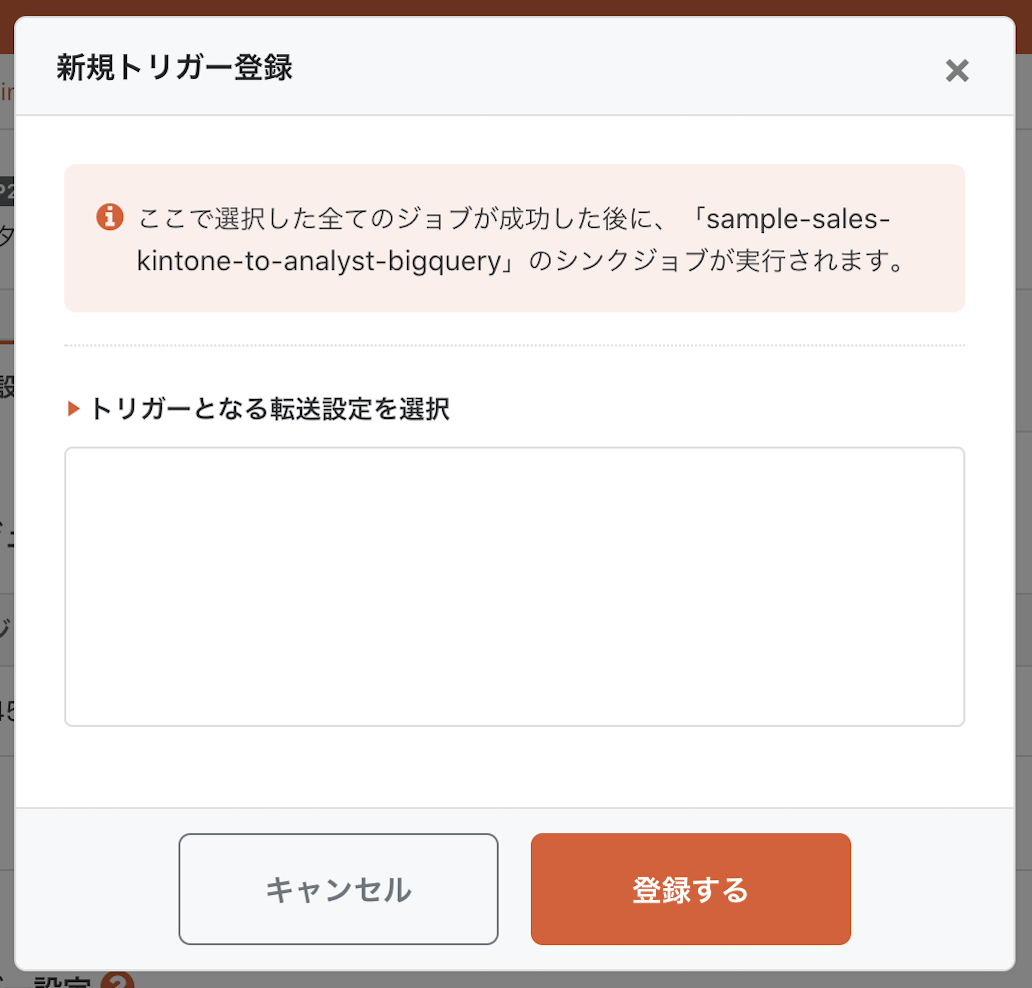
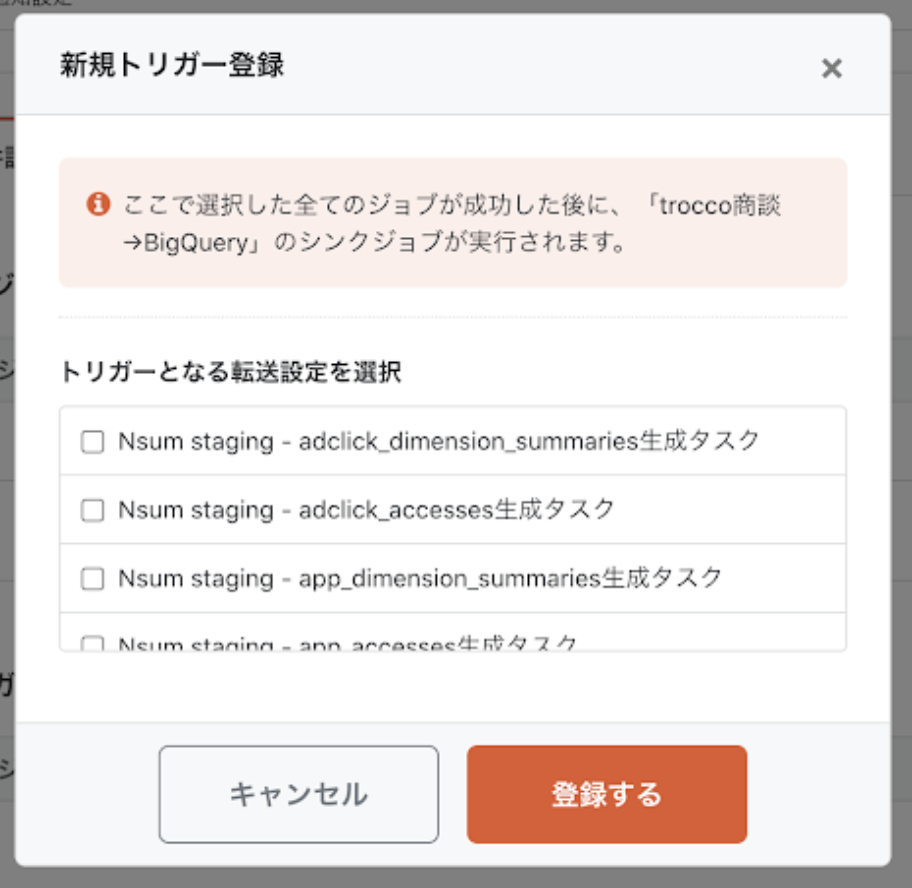
次に通知設定を行います。今のところメールとSlackに対応しています。
用途に合わせた通知の設定を行うことができます。
- 接続テスト:転送成功時、debug用のSlackチャンネルに通知を送る。
- 本番稼働中:エラー発生時、alert用チャンネルで運用担当にメンション通知を送る。
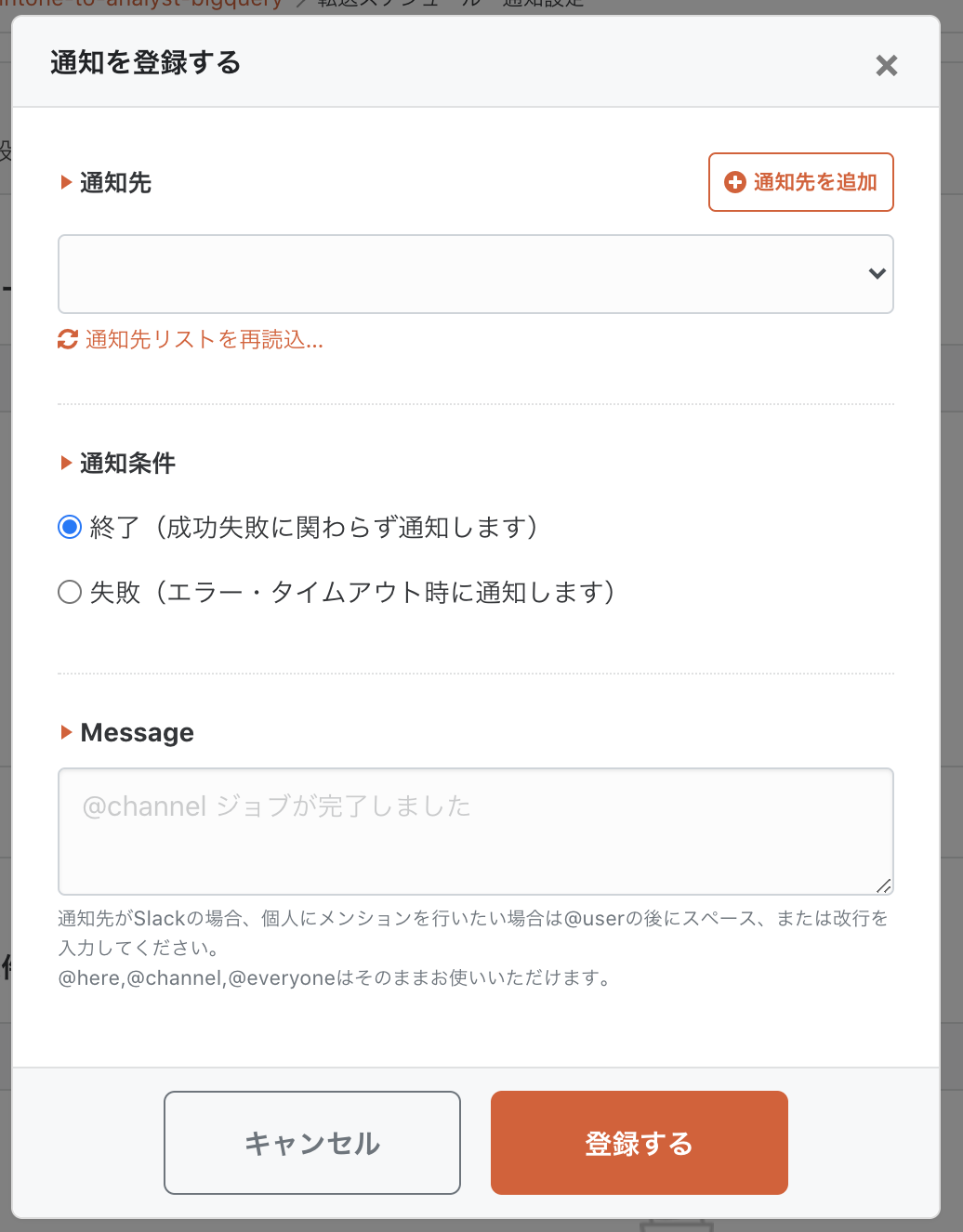
レコード件数を通知条件に設定することも可能です。
外部サイトがレポート用のCSVを置いてくれるけど、たまに中身が空なんだよなぁ、といった場合、システム処理はエラーにならず、0件で更新されてしまいます。そういったときに、件数ベースでの監視を行うことができます。
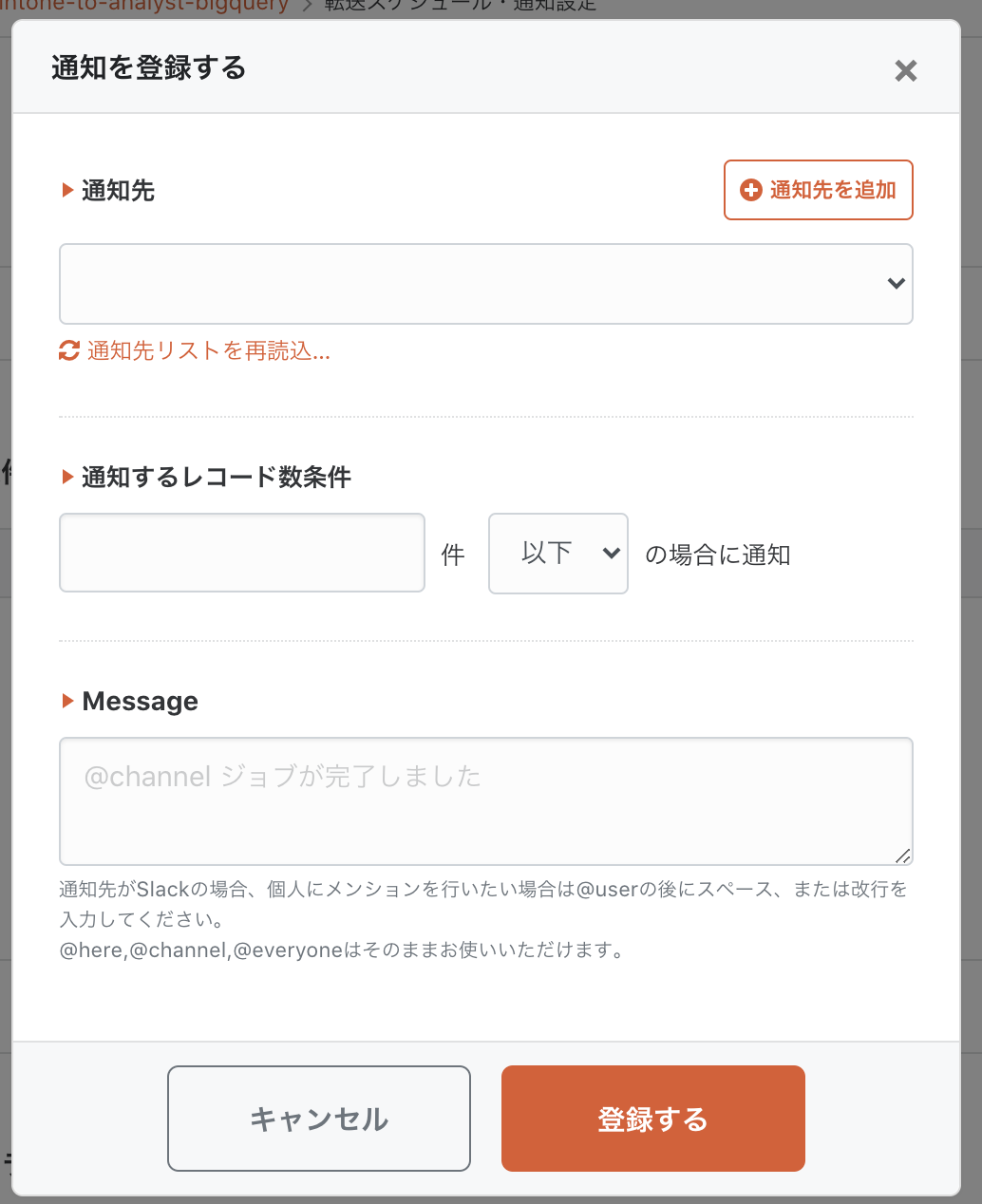
また、ジョブ実行から一定時間経過で通知を送ることもできます。
朝8時に集計を始める。朝9時の出社時間までに集計を終わらせたい。間に合わなければ経営企画チームのSlackチャンネルに「遅延しています」と伝える。こういったサービスレベル(SLA)・オペレーショナルレベル(OLA)に応じた一連の流れをシステムで管理できます。
ジョブ実行とトラブルシューティング
以上でジョブ作成は完了です。無事に設定が読み込まれて、次回実行日時が表示されているのが分かります。疎通テストを行いたいので、右上の「実行」ボタンで、ジョブを走らせます。

ジョブが実行されると、リアルタイムでログが画面に表示されます。最初の4行ではTROCCOの実行環境が立ち上がっていることが分かります。それ以降はEmbulkのログで、自分でEmbulkのサーバを立てて使う場合と同じログが出力されます。

ジョブが失敗しました。エラーメッセージが表示されています。メッセージには「$id」というカラム名がBigQueryのフォーマットに適していないことが指摘されています。よく分からない場合は、TROCCOのサポート担当がSlackでサポート対応してくださるそうです。

エラーの原因はSTEP2で飛ばした箇所でした。kintoneのデータのうち、レコードidや更新日時といったメタデータは、接頭辞が「$」マークになっています。一方で、BigQueryはカラムに「$」マークを指定することができません。デフォルトのカラム名でデータ連携を行うとエラーになります。

元カラム「$id」そのままではなく、カラム名「id」に書き換えてみましょう。

設定を変更して再実行すると、今度は無事に成功しました。近年のSaaS / iPaaSと同様に、TROCCOもジョブ実行履歴が見やすいです。
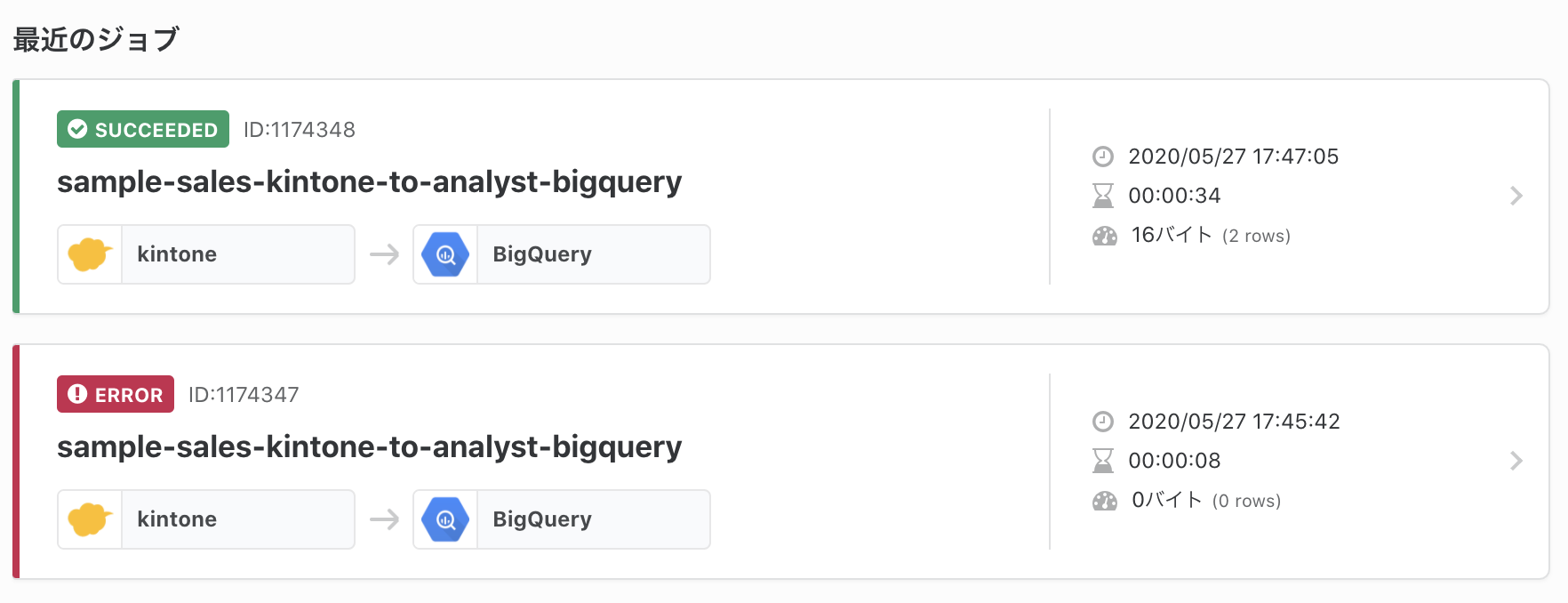
BigQueryを確認すると、指定したデータセット・テーブル・カラムが作成されて、データが反映できていることが分かります。作業は15分程度で完了しました。すごい。

他の画面・機能について
一息ついてトップページに戻ります。ダッシュボードはこのようになっています。ゆずたそ様トライアル用様ご契約プランです。Twitterのタイムラインを埋め込んでアップデート情報を伝えるのは賢いなぁと思いました。せっかくなので他の画面や機能を見ていきましょう。

転送設定の一覧です。検索によって表示を絞り込むことができるので「kintoneからデータを転送しているジョブを棚卸ししよう」「BigQueryにデータ転送しているジョブはどれだっけ」といったユースケースで役立ちそうです。

データマート定義と呼ばれる機能です。一言でいうと「集計済みテーブル」作成の機能です。RedshiftやBigQueryに格納されたデータを集計して、RedshiftやBigQueryの別テーブルに保存することができるそうです。
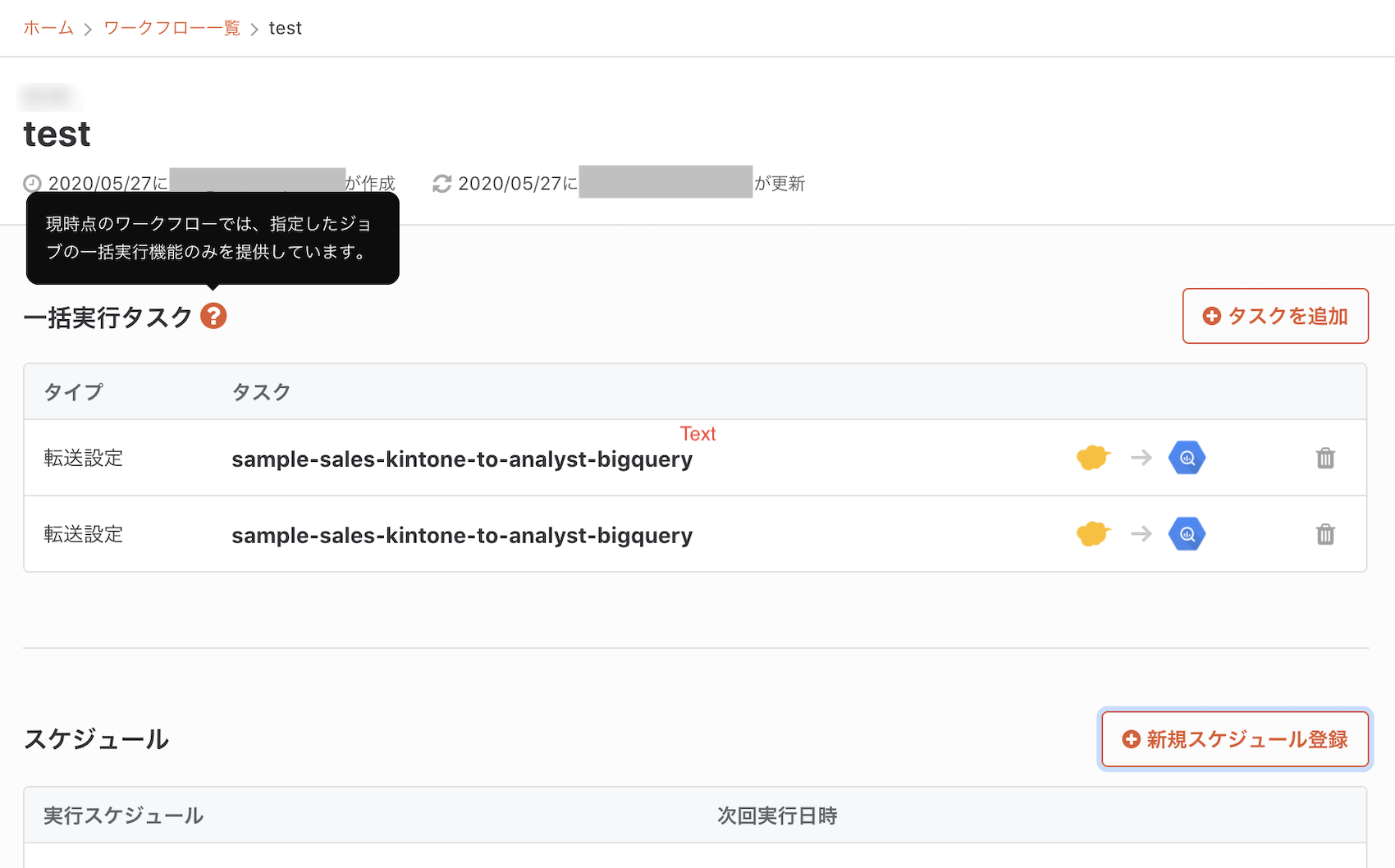
「ワークフロー」と呼ばれる機能です。現状は指定したスケジュールで複数ジョブを一括実行できます。近いうちにアップデートが行われる予定だとのことで「ジョブAが終わったらジョブBを実行する」といった形のワークフローを簡単に管理できるようになるとのことです。
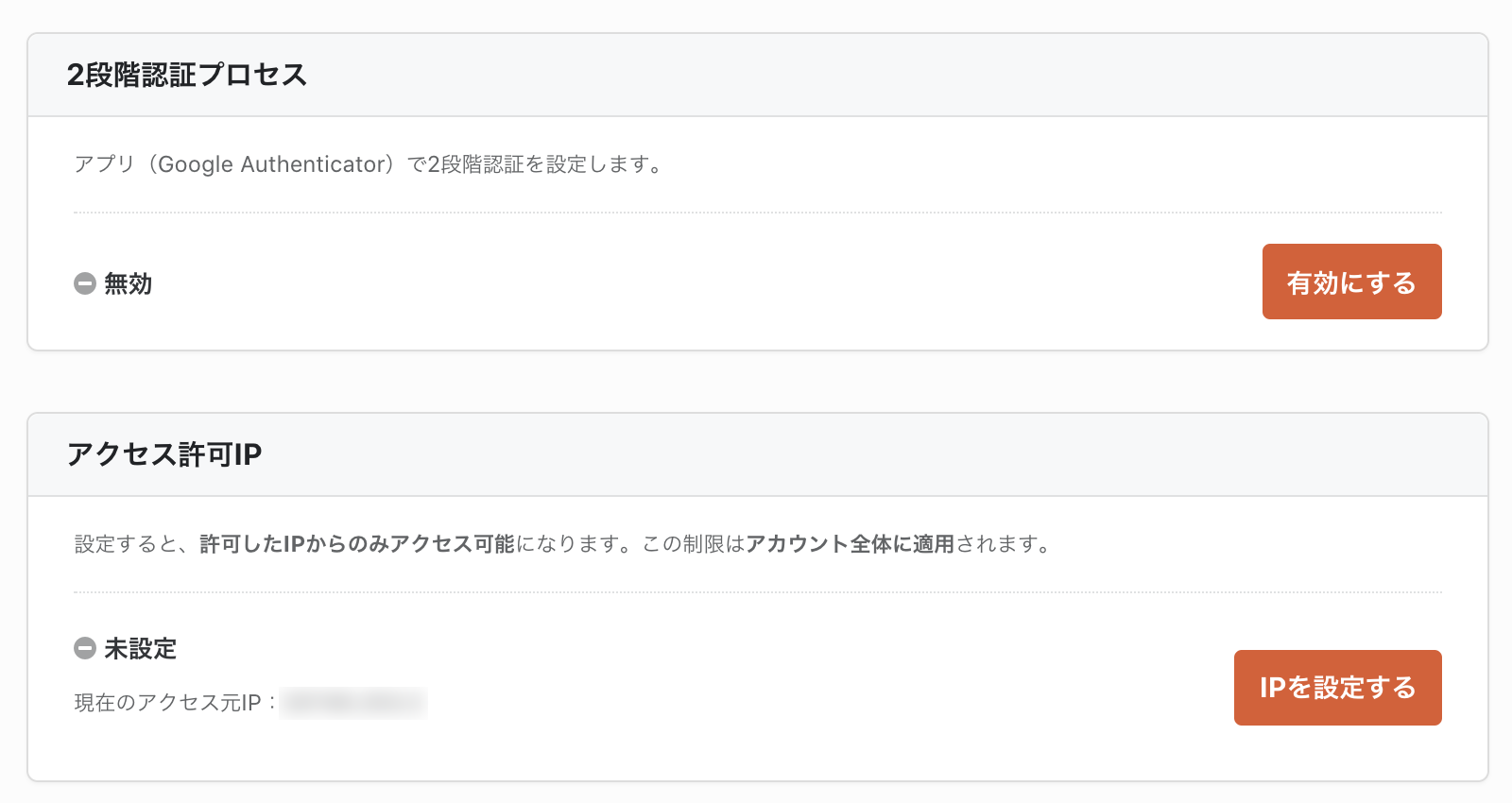
設定画面では2段階認証やIPアドレス制限を行えます。仕事でデータを扱うなら必須です。
設定ファイルをJSONでエクスポートする機能もあります。将来的にはTROCCOの設定をGitHubでコード管理できるように機能拡充するとのことです。そうなると社内の既存ワークフローの延長でデータ連携を行えるようになります。プルリクエストを通してのレビューや履歴管理も可能になるため、ガバナンス・品質向上に直結します。

ちなみにこのエクスポート機能ですが、ベンダーロックインを回避できるという意味でも、利用者観点では非常にありがたいです。言い換えると「不満があったらいつでも安心して退会できますよ」という機能です。利用者の不満を減らして、長く使い続けてもらうために、運営者が改善にコミットしている証でもあると思います。
おわりに
ということで、簡単にデータ転送を完了できました。同じように、kintoneの本番営業データをBigQueryに集約して、Lookerでダッシュボードを表示すれば、当初目的は達成できそうです。
気軽に試せない有料ツールですので、これまで利用イメージが湧きにくかった、というのが正直なところです。そこで今回は意図的に1つ1つの画面を細かく見ていきました。TROCCO利用を検討中の方々には、ぜひ参考にしていただけると幸いです。
次回は「使ってみての感想」を座談会形式でお伝えできればと思います。