
第10回では「王道BIツール特集- Tableau/PowerBI/Googleデータポータル」と題して、王道のBIツールとしてTableau / PowerBI / Googleデータポータル(現:Looker Studio)の3つのBIツールをピックアップし、実際にそのツールを業務で使われている企業の方に事例講演を行っていただきました。
第11回は「「6社のデータエンジニアが振り返る2021」と題して、6名の方々から今年1年をKPTに沿って振りかっていただきました。
今回は年末というタイミングですので、データエンジニアリング・データ分析基盤に関する「良かったこと・問題だったこと・来年トライしたいこと」(KPT)をLT形式で発表して頂きます。
プロの現場で活躍されているデータエンジニアの皆様の生の声を聞ける場となっております。
LT1「レガシー化したdata pipelineの廃止」
永井 伸弥 氏
データ基盤に制限なくデータセットを追加して行けば、運用コストは際限なく膨らんでいきます。
株式会社メルカリ JP Analyst
そこで必要になるのが、不要になったデータセットの廃止です。
この発表では、株式会社メルカリにおいて日次の利用者が150名以上居たデータセットをどのように廃止したのか事例を紹介します。
Twitterのアカウントはこちら
はじめに、メルカリのデータ活用の現状についてご説明いただきました。
創立当初からデータを利用し、データパイプラインが複数の系統がある

永井 伸弥氏:「メルカリのデータの基盤はBigQueryを中心としており、メルカリやメルペイ等の複数の本番環境からBigQueryにデータをアップロードしています。そしてBigQueryのコンソールからSQLを実行し、Lookerを通じてデータを利用する環境になってます。
こうした背景には、メルカリは創業当時から非常にデータを重視した文化があり、アナリストや MLエンジニアの方々以外にカスタマーサポートやプロダクトマネージャーの方々もデータを利用することが活発に行なわれていて、BigQueryのユーザー数が月間で800名を超えるほどの規模になっています。」
今回は複数あるデータパイプラインの中で一番古いものを廃止した事例についてお話していただきました。
レガシー化したデータパイプラインの廃止の難しさ

永井 伸弥氏:「一番古いパイプラインはいくつかの問題点を抱えていて、ワークフローエンジンがnode.jsによる独自実装で独特な構成のもので、開発開始から8年が経過していることもあり、運用コストと障害のリスクが高い状態になっていました。
しかし、廃止するには難しい事情が大きく分けて2つありました。1つ目がこのデータパイプラインから生成しているデータを他のデータパイプラインで再現することが困難だったためです。このデータパイプラインは本番環境からBigQueryにアップロードする過程でデータ加工も行い、加工のロジックがソースコードの複数の箇所を確認する必要があったため再現することが困難という問題がありました。
また、バッヂで定期的にデータをアップロードしていましたが、データがバッヂの動作するタイミングに依存した内容になっていたため再現が困難でした。データセットの利用者が広範囲なため、このデータセットから集計したKPI周りの業務が多く存在したので、仕様をシンプルにして廃止することは難しい状況がありました。」
技術的に無理がなく、業務上十分な仕様を作る

永井 伸弥氏:「データセットを廃止するために、技術的な要件と業務的な要件のトレードオフを考慮した上で「技術的に無理がなく、業務上十分な仕様」を作る必要がありました。
新しい仕様を作るためにアナリティクスチームはヒアリングを通じた業務理解を行っていくと同時に、「誰にヒアリングしていけば抜け漏れなく用件を洗い出せるか」を調べるためにBigQueryのjob historyを分析し、利用者を特定した上で分析を行うことを繰り返ししました。」
利用者数のモニタリング

永井 伸弥氏:「テーブル利用者が150名以上いたので、周知するだけでは新しいテーブルへの移行がなかなか進まないのが実情でした。この課題に対しても、job historyを分析して利用者数をモニタリングしながらPDCAを回していきました。具体的には利用者数の推移を見ながら、利用者数を減らすような声がけ・施策を打ちつつ、利用者数のモニタリングして改善を繰り返していくことをしていました。」
この取り組みの意義と趣旨であるKPTについてお話しいただきました。
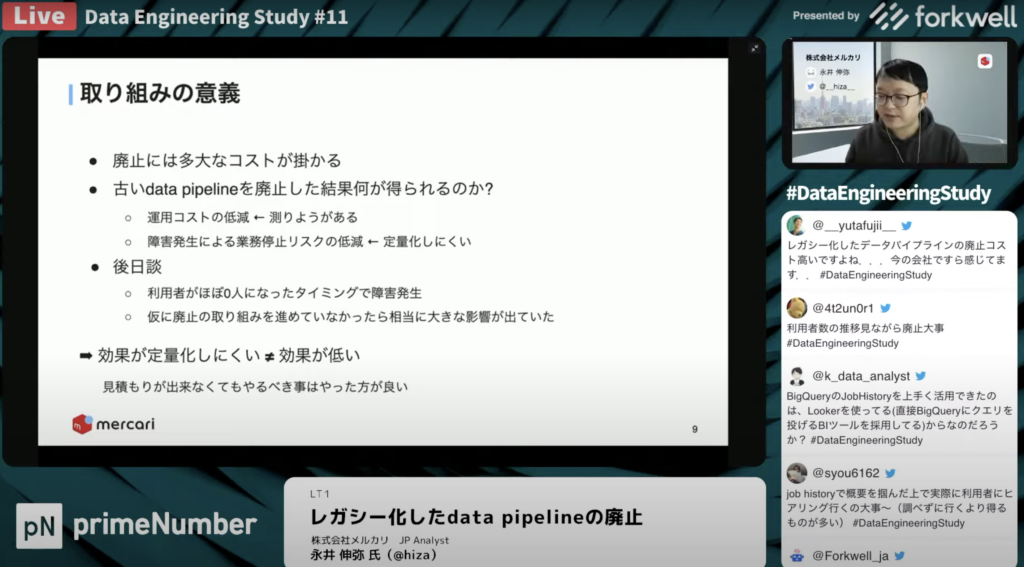
永井 伸弥氏:「パイプラインの廃止には時間や労力の多大なコストがかかります。業務に影響が出ないように新しく仕様やKPIを作り直した上で、全社で使っているKPIも定義変更を行いました。
一方で、このような取り組みに対して、どういったリターンが得られるかは定量的に表現しにくいです。障害発生による業務リスクがどの程度低減できたかを定量的に表現するのは難しいですが、この取り組みにおける効果が低いという意味ではないので、改善を続けていく必要があります。
最後にKPTで整理すると、こういったアプローチをしていく際は人に話を聞いていくといった泥臭い取り組みに加えて、データがどう使われているのかを分析するデータを使ったアプローチもキープして行きたいポイントです。
Problemとしては、こういった取り組みをより効率的に進めていくべきだと考えています。今後のTryとして、今はBigQueryのjob historyや監査ログを分析していますが、メルカリの人事情報を統合することでどのチームでどの様に使っているかをデータから調べられるようにしていきたいと考えています。」
LT2「複数データ基盤の透明化」
山田 雄 氏
株式会社リクルートは2021年に統合され、現状複数のデータ基盤が存在しています。
株式会社リクルート データエンジニア
同じような開発、同じ課題に対するアプローチなど、いわゆる車輪の再発明を防ぐために行っている取り組みや、今後どのようにしていきたいかなどを紹介します。
Twitterのアカウントはこちら
はじめに株式会社リクルートについてご紹介いただきました。
様々な子会社が統合され株式会社リクルートに

山田 雄氏:「今まで様々な子会社がありましたが、統合して株式会社リクルートになりました。それぞれが予算やデータ基盤を持った独立した会社だったので、会社統合に合わせてデータ基盤の統合はすぐにはできず、データ基盤は複数あるという状態になっています。また他の会社のデータ基盤をどういう人が開発してるのかが不明瞭な状態でした。」
統合したことによる基盤の問題

山田 雄氏:「統合した際に「見える化」を目的としたアセスメントを実施しました。インフラバージョンアップした時にバージョンアップに対するテストが書かれているかの質問や、データ基盤の乗り換えへの方針対応を各基盤に対して行いました。それらに加えて、ESOL対応方針やCI/CD環境についてもアセスメントを実施しました。
それによってインフラのライフサイクル管理やセキュリティ設定が基盤ごとに異なっていて、スコアリングをしてレポートすると完璧な基盤はなかったものの、ミックスさせていいとこ取りをすることで良い基盤になるとわかりました。」
勉強会を通して基盤の理解を進める

山田 雄氏:「横の基盤を知るために2021年6月ごろから勉強会を社内で開催し、毎月違う基盤を共有して、参加人数は約300人になりました。株式会社リクルートだけでなくグループ会社の基盤の紹介も行っています。
複数のアーキテクチャがドキュメント化されてことで、誰でもすぐに基盤のアーキテクチャを見れるようになりました。勉強会するにあたって、最新のアーキテクチャ図を作成してもらい、全てがドキュメント化されて一箇所に集まっています。
いいアーキテクチャーのソースを共有してもらえるようになったのも、TTPのすごくいいところだと考えています。また、発表してる人が基盤を担当していることがわかるので、相談先の明確化ができています。」
最後に、今後の展望と社外での取り組みについてお話しいただきました。
コミュニティを活性化させる
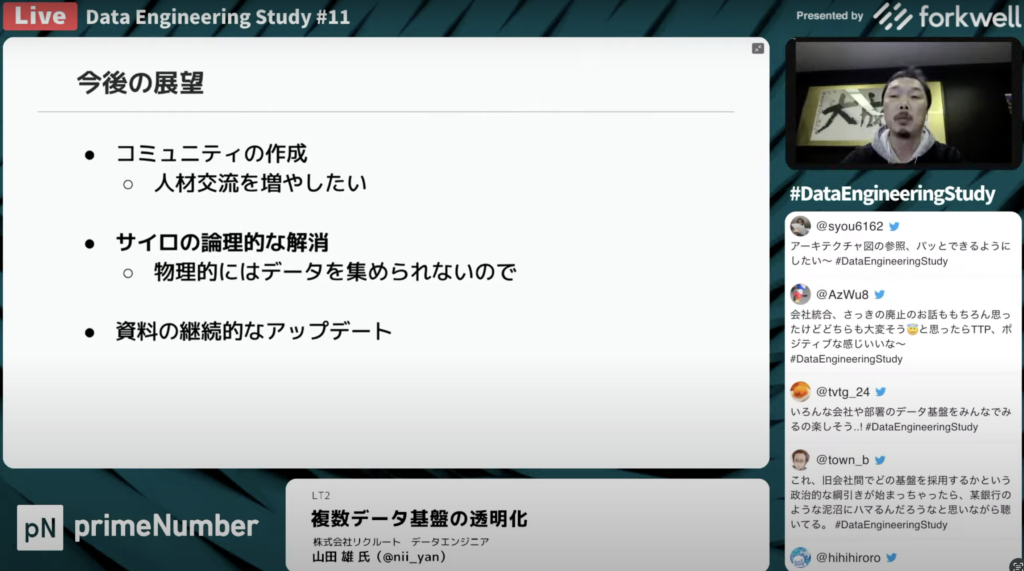
山田 雄氏:「こういった透明化は全ての基盤ではできてないので続けていきたいと考えています。今後の展望としてはコミュニティのような形で人材交流を増やしていけたらと考えており、普段からの交流頻度を増やせる取り組みをしていきたいです。
特に力を入れたいこととしては、データのサイロ化を論理的に解消していくことです。元々散らばっているデータを物理的に集めるのは不可能だと考えているので、データガバナンス化を進めていき、マイクロサービスの集合体としてうまく機能してるものを作れたらと考えています。
そのほかにも、BQ Update勉強会でまとめたアップデート内容を社内で共有したり、Tipsや社内事情についても共有しています。」
社外での取り組み
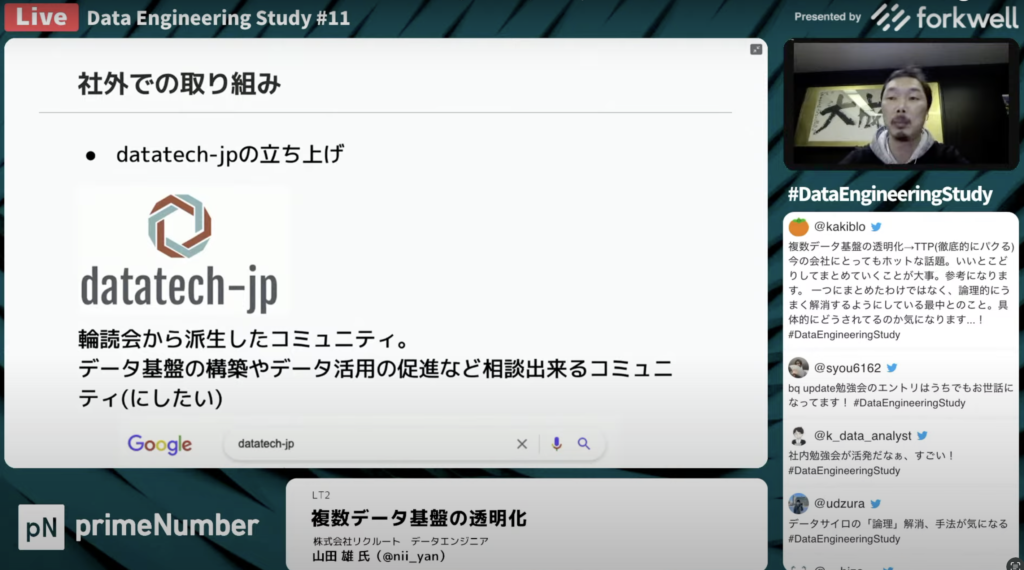
山田 雄氏:「輪読会だけでなく、データエンジニアやデータを扱う人のコミュニティを形成したいと思い、datatech-jpを立ち上げました。「data management at scale」の輪読会も行なったりしているので、興味のある方はコミュニティに参加していただきたいです。」
LT3「dbtを活用したデータ基盤の論理・物理設計の現在地と振り返り」
田中 聡太郎 氏
Ubieでは、データ基盤の実装にdbtやAirflowをはじめとした様々なツールを利用しています。
Ubie株式会社 データエンジニア
今回はその中でも、特にdbtを活用したデータ基盤の論理・物理設計について、導入初期から現在に至るまでを簡単に振り返りながらご紹介します。
Twitterのアカウントはこちら
はじめに、本日お話しいただきく内容についてまとめていただきました。

田中 聡太郎氏:「Ubieが提供しているデータ基盤について設計面から紹介します。流れとして、現在地に至るまでの変遷に関して、一年前Ubieの分析基盤とその後V1の分析基盤の構成、最後に良かった点・困ってることです。」
現在のUbieデータ分析基盤

田中 聡太郎氏:「現在地としては図のような構成になっていて、ここに向かっていく上でどういう曲折があったのかの話になってきます。」
1年前のデータ分析基盤の課題

田中 聡太郎氏:「1年前の構成はデータレイクにソースやログテーブル、dbのタンクテーブルが入っていて、そこからクエリ一発で様々なマートを作るシンプルな構成になっており、SQLの実行はAirflowで提供していました。
明確な課題としては、再利用性が低いところです。利用者が増えていくのに対してニーズに応えられなくなっていました。分析用途のマートの作成構造が起因して、似たような処理があるユースケースがあった際に、作り直したり別のクエリを書く必要がありました。また、1つのクエリやコードの中に様々な目的の処理が入っていたので、テストする時に入力条件による抽出や条件の掛け合わせが難しくなっていました。 」
再利用性と保守性を意識した設計に

田中 聡太郎氏:「V1からdbtを採用し、データレイクからDWHのテーブルを作ってマートまで作るところを一気通貫で実行して、各所でテストを挟むような構成になってます。データレイク・DWH・マートの3層構造とdbtを採用したことで、再利用性が向上し、dbtテストによる保守性も上がりました。」
更なる課題に直面する

田中 聡太郎氏:「複数の目的を持った処理が一つのクエリに混在したことで、先の1つ目の課題が部分的にクリアできていませんでした。3層構造ではDWH層に様々な目的を持った加工処理を集中してSQLクエリに問題が発生したり、DWHとデータマートのどちらに実装すべきかが難しいという課題がありました。
1つ目は汎用的な共通処理はどこでやるかという点です。日本のサービスだとUTCで記録されたタイムスタンプをJSTに変換したり、欠損値・NULLのチェック、不正な値の排除などの処理をどの層でやるべきかが明確化できていませんでした。また、定義が1つの場所にまとまってない問題もありました。
2つ目は扱っているドメイン特有の関心事をどこにまとめるかという点です。分析上はA機能とB機能の両方を使ってる率やA機能を使った後、B機能を使っている人の数を出したいが別々のドメインに存在するような事例があったとします。この時に、集計をするためのDWHやデータマートをどう作り、どのように結合するのかは3層構造だけで定義するのは難しく、結果的に再利用もしにくくなる課題がありました。」
DWHに押し込められた加工処理を明確して再設計

田中 聡太郎氏:「左側のrestrictedは個人情報等をマスクするもので、データ基盤は右側の白い四角で囲われた部分になります。」
現在の構成における各層の詳細を解説いただきました。
1:Interface層

田中 聡太郎氏:「Interface層はタイムスタンプ変換等を行うログテーブルで、この層を設けることでログテーブルに対して毎回スタンプの変換や欠損を考える必要がありません。やってることは特定のデータモデルに依存しないような共通の処理や無効な値の排除を行なっています。」
2:Component層

田中 聡太郎氏:「Componet層では、再利用性を意識して特定のデータモデルを表現しています。これは複数のDWH層で利用されることを意識して作られています。
例えば医療系のスタートアップであるUbieでは、問診や医療機関を検索するドメインのイベントを表現したテーブルに集まっています。これらはスタースキーマのDimesionとFactに分かれていて、Conformed DimensionとConformed Factは基板内で互換性を持って整備したものです。
Dimensionの代表的なものとして、キャンペーンコードや医療機関のリストなどのマスターデータが挙げられ、Factの方は問診のイベントレコード・検索レコードが該当します。
これらがComponet層にまとまっており、この層を使って分析のベースとなるテーブルのDWHを作っています。分析を行いたい場合は、DWH層にあるテーブルを使って分析し、Componet層はドメインに詳しい分析者が整備する形になっています。
DWH層のポイントとしては可視化を意識しないところです。ユースケースを考慮した設計にはせず、あるドメインの分析をしたいとなった時に必要なコンポーネントを結合に止めています。これによって、当該ドメインに詳しくなくても触れることができ、他ドメインの担当者とかでも利用できるようにセーブしています。」
3:DataMart層

田中 聡太郎氏:「DataMart層は特定の分析や可視化を見せて整備をしています。DataMart層では大きく2つの役割のものを作っていて、ドリルダウン前提のローレベルでイベント単位でレコード記録されているマートとヘルスチェックとかダッシュボードで可視化する際に事前にMetricsを集計済みのマートを作ったりしています。
サービスの基本的なMetricsは変化が少ないので、事前集計済みなもの用意し、それらをMetrics Martと呼んでいます。Metrics Martを作ることでdbtでの数値の一貫性のテストがしやすくなったり、BIツールでの集計時に闇集計を回避することができます。」
各層でdbtテストを仕込んでいる

田中 聡太郎氏:「データの完全性を調べるためのレコードの欠損やrequiredなカラムに値が入ってるのかのテストは基本的にComponet層で実装していて、ドメインの関心ごとも再度チェックします。
一貫性はMetrics Martで複数レポート間で指標値がずれていないかをテストしていて、データの鮮度はInterFace層に実装して、freshness testをしています。
こういった構成を取ったことで、各層の責務が明確化されてその処理の実装漏れがなくなり、高品質なデータを提供できるようになりました。また、責務が明確であることはテストの書きやすさにもつながります。」
一方で、課題となる点も残っていると言います。

田中 聡太郎氏:「設計はできましたが、この設計に則ってモデリングできているのはUbieが扱っている中で一部で、特にComponent層とDWH層の境界のモデリングが難しく、さらに高い技術が必要だと考えています。興味ある方は連絡をいただけると助かります。」
LT4「フルスタック一人目データアナリストがデータ基盤を作ったお話」
Sho Maekawa 氏
以下についてお話し予定
株式会社オープンエイト/データストラテジスト
・ データアナリストがBQデータ基盤へリプレイス
・ データエンジニア+データアナリストMIX体制
・ ビジネスオペレーションの構築も兼務
・ BIやSQLだけでなく、データ連携も民主化するために最初からtroccoを選択
Twitter・YouTube
プロダクト紹介

Sho Maekawa氏:「株式会社オープンエイトは動画制作ツールの「VideoBRAIN」というプロダクトを運営しています。動画制作の経験のないマーケターの方がPR動画作ったり、人事の方が採用動画を作るなどといった動画による課題解決を図っているプロダクトです。自分たちの業務の中でこの動画ツールを使っていて、データの民主化のためのドキュメント動画で作ったりもしています。」
1人目のデータアナリストとして入社した理由

Sho Maekawa氏:「今回の内容を伝えたい対象は、ベンチャーの1人目データ人材になるか迷ってる方やこういった話を聞いてみたい方です。
1年前に入社した際は、自分が1人目のデータアナリストでした。当時はデータ基盤が野良環境のみで、KPIの定義もバラバラ、そしてデータは一部見れなくてもしょうがないといったスタートアップの初期のフェーズで、改善しなきゃいけないことが多い状態でした。
こういった事はある程度覚悟していて、それでも1人目で入社した理由は、ゼロからデータ基盤や戦略まで繋ぎ込むところを経験できるのはとても貴重だと考えたためです。
前職ではデータ可視化の部分に特化してスキルアップさせてもらっていたが、どんどん強い企業にデータ人材が集まって高度化していく中で、経験を積めば積むほど最初の大変なフェーズに挑戦する人はそこまでいないと考え、これはチャンスなんじゃないかと思いました。 」
1人目でもチームで動くことを前提に

Sho Maekawa氏:「一年振り返ってみてやってよかった事は、初めからチームでの開発を意識した事でした。最初は忙しすぎるのでアウトプットを出すだけになってしまったり、エラーが起きているEmbulkを防ぐ未然に防ぐだけになってしまう事が往々としてあります。しかし、次に入ってくる人のことを意識してConfluenceでドキュメント管理するなどして行動をメンテナンスを出来る範囲でやっておいたのはすごく良かったと思います。
また、データ基盤の育ちとデータの民主化をコントロールできたのも良かったです。やることがいっぱいある中で、データ基盤だけ育てていっても意思決定が進まず、民主化を進めて行ったりアウトプットを出す事ばっかりやっていても基盤が育たないので、コントロールすごい大事だなと思います。」
反省点もある
Sho Maekawa氏:「反省点としてはKPIの自動取得のプロジェクトの失敗があります。初期の段階で、SaaSの費用を毎回salesforceなどのデータから自動集計するような仕組みをつくろうとしましたが、新しい仕様に落とし込めなかったり、データ取得できないなどがありました。
データ基盤の構築は前職のヤフーで見てきたものを意識しましたが、データ基盤の状態をDMBOKの観点で整理してロードマップを作って最初から立ち上げることはできませんでした。
また、KPIの自動取得のプロジェクトでデータ基盤を作っていくために、コードを書くことに専念したかったですが、それらを変更したり翻訳する役割とデータ基盤を作る役割を一人でするのは難しかったです。」
また、社内の人に対してのデータ基盤の必要性も解いてきたとお話しいただきました。
データ基盤の刷新

Sho Maekawa氏:「データ基盤の業務に携わる人以外に対しては資料を使って説明していくことで、いきなりのレコメンドが来るのを防ぎました。1か月続けると変な依頼は減り、改めて基礎的な資料を用意しておくのは大切だと感じました。
入社前のデータ基盤は図のようになっていて、左側にあるVideoBRAINのプロダクトのデータをEmbulkを使って、仮想環境に転送し、それをTableauやスプレッドシートなどに展開しています。
データレイク・DWH・データマートの3層構造はとっておらず、 DWHの役割とマートに分かれている集計もあれば一つにまとまっている集計もあったり、Salesforceのデータを仮想環境の野良DWHの環境に一回挟んでいるものもあれば直でTableauに繋げているものもあったので、経路を整理する必要がありました。」
trocco®とBigQueryの導入
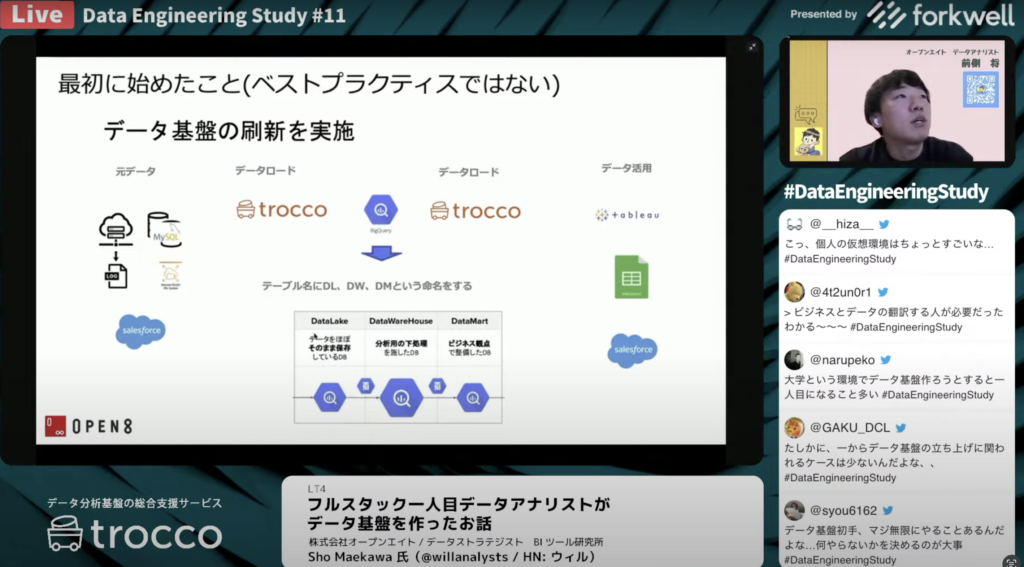
Sho Maekawa氏:「ここで意識したのは、データレイク・DWH・データマートで役割を分けるということで、今後はデータをセットごとに権限を振ってデータレイク・DWH・データマートに移し替えていく予定です。
大元のデータソースから着手したかったですが、KPI自動取得のプロジェクトでうまくいかなくて早く進まないところがあったので、自分たちができる経路整理でデータ基盤を先に作りました。その後に、Tableauやスプレッドシートのデータを新しいBigQueryのものに差し替えました。
主要なアウトプットはリプレースのタイミングを事前に決めて、事前に確認してもらって一気に差し替えを行いました。並行期間の2か月の間に野良アウトプットを使ってお客さんに展開するケースが発覚したので、一気に使ってないものを廃止しました。」
現在の体制

Sho Maekawa氏:「現在は4人のチーム体制になっています。特徴としてはデータエンジニアとアナリストを両方兼務できる人を3人採用しています。 さらにアナリスト寄りのツールであるtrocco®を使うようにしています。
初期の立ち上げのフェーズだと、急な集計依頼が来たり一気にデータ基盤を変えたいという要望があってので、ロードマップ通りに進まないことがありました。そのため、エンジニアのリソースが必要になるタイミングとアナリストのリソースが必要になるタイミングがばらばらだったので、両方できる人がこの時点では必要でした。
後は全員若手なので今は幅広く手をつけていき、いずれかのタイミングで専門性を持てるようにチームを作れるように考えています。」
社内データを上流から管理

Sho Maekawa氏:「オープンエイトのデータチームの特徴としては、Salesforceなどのビジネス部門のツールの管理やオペレーション改善なども役割に含まれています。 社内データを上流から抑えこむことができるのがメリットとしてあります。
これによってデータ基盤に合った形でSalesforceを設計でき、ルールもデータチームで作っているのでOpsの役割をもっと人と上手く役割分担していくことで今後も安定して連携ができそうっていう部分ではすごい良かったと考えています。」
最後に、挑戦したいことについてお話しいただきました。
挑戦したいこと

Sho Maekawa氏:「今後挑戦していきたいこととして、プロダクトの更なる分析があります。この1年地道な作業が多かったので、もっと腰を据えて分析していきたいです。」
LT5「データ基盤品質向上のための一年」
土川 稔生 氏
タイミーのデータ基盤はEmbulkとDigdagを用いたBigQueryを中心としたDWH、 Redashとデータポータルを用いた分析基盤を使用していました。しかしデータの品質を中心として様々な課題にあたり、ここ1年でLooker, dbt Cloud, trocco®の導入を行い、課題解決を試みました。
株式会社タイミー
このLTで導入した経緯、振り返りを行い、近いフェーズの基盤開発の参考になれば嬉しいです。
Twitterのアカウントはこちら
今回は、タイミーで今年発生したデータ基盤の品質低下につながる問題をと対策を時系列順に振り返っていただきました。またデータ品質の詳細はこちらの記事にて解説しております。
1年前のタイミーのデータ基盤

土川 稔生氏:「タイミーはEmbulkとDigdagをAWS上に設けて、Emblukがマスキングを含めた加工処理などを行い、BigQueryでデータを収集してます。それをRedashやデータポータル(現:Looker Studio)、BIツールにつないで可視化を行っていました。」
データ品質に関して起こった問題

土川 稔生氏:「ここで起こった問題として、更新タイミングがデータソースコードでかなり遅延しました。
途中に監視はいくつか入れていましたが、インフラやパイプラインでのバグの発生量が多く、監視が追いつかなくなっていたので、更新頻度の監視とSLO/SLAの導入をしました。
適時性をSLIで定義して、各データソースごとにSLAを分析者と定義しました。期待していたこととしてはエラーバジェットを設けて新規開発に時間を割けるようになることやSLAを違反した時にポストモーテムを導入して改善を図って行ったり、SLOをDREチームが守っていくことでSLAを担保して行くような構成に変えました。
SLI・SLO・SLAの定義

土川 稔生氏:「SLI・SLA・SLOの一般的な定義として、SLIがサービスの品質を守るための指標で、SLAがその指標に関するサービス提供者等の契約で破ったときにどうするかなどを定義します。SLOはそのSLAで提示した指標の具体的な目安になっています。
これをDREチームなりに解釈すると、SLIがデータパイプラインの適時性を示していて、データソースの転送元の更新からどれぐらい遅れて転送先で実用可能になるかで定義しています。SLAはサービス使用者と分析者で適正に関する契約を結び、破った場合はポストモーテムを実施すると決めてます。SLOはDREチーム内で決定されたデータソースごとの目標になっています。」
具体的に適時性の監視をどのように行なったのかをお話しいただきました。
適時性の監視の基盤

土川 稔生氏:「BigQueryがデータレイクとして真ん中にあり、データソースごとにSLAとSLOを定義しています。PythonのスクリプトがGithub Actionsで定期実行されて、今の時刻とBigQueryにあるメタデータの最終更新時間を比較してデータソースごとにSLAを担保できるかをチェックしていきます。
SLAが担保できない場合はSlackでDREチームにメンション飛ばして障害対応を行い、SLAを破っている場合はポストモーテムを設けます。」
取り組みを通した振り返り
土川 稔生氏:「このような取り組みによって、分析者もデータ転送時間を把握しながら分析が可能になりました。DREチームも障害対応と新規開発のバランスを保ちながら、どちらも効率よく進める事ができました。」
次に、データ品質に関する別の問題点を取り上げていただきました。
データ活用の活発化によるクエリの再利用

土川 稔生氏:「次に起こった問題は分析が活発になるにつれて、分析チームにすごい依頼が増えていくという事例が発生しました。分析チームはクエリの作成・修正やダッシュボードの作成を行っていますが、Redashが再利用されるケースが多く、それに伴いクエリのズレも発生しました。
これを解決するためにLookerを導入し、事前にSQLを定義してあげることでクエリの書き方によるズレを減らしたり、あとは誰でもダッシュボードに簡単に作成することによってデータ活用の促進を期待していました。」
Lookerの導入について

土川 稔生氏:「データを収集しているBigQueryが左にあって、可視化するにLookerが増えた形になります。やったこととしては、Look MLによるSQL定義の一本化、Exploreによるダッシュボード作成の簡易化、そしてRedashでダッシュボードが乱立していたのでLookerに少しずつ置換したなどがあります。
あとは、Look MLで定義した指標を一部BigQueryに吐き出すことができるので、それをDWHとして運用も進めていました。」
Looker導入に対する振り返り

土川 稔生氏:「Lookerの導入によってダッシュボードを品質高く、誰でも簡単に分析することができるようになりました。LookerからBigQueryにDWHとして吐き出すことで、連携しているデータポータルやredash等でそれらを参照するときのデータの品質を高くなりました。
導入の際、Look MLはSQLを基本としているのでキャッチアップは簡単でしたが、設計が難しく何度か全体の設計のやり戻しが発生しました。 また、ダッシュボードの移行は難しくて苦戦中です。
また、Lookerはコミュニティ広くて他社さんや他のサポートも手厚いのがすごく助かりました。」
dbt Cloudの導入によって解決

土川 稔生氏:「次にEmbulkが行っている加工の処理のツールの依存性・肥大化・不透明性が問題になってきました。
データ量が増えていくことによって、Embulkが行っている加工処理が遅れ、実行時間や更新頻度のボトルネックになってきました。また、他のパイプラインにtrocco®を使ってヘッドパイプラインを構築した際に、T処理がEmbulkに依存してしまうと、一元管理ができないのも問題でした。
そこでdbt Cloudを導入して、これを解決をしようとしました。Embulkで行っていた加工処理をdbt Cloudに全部持たせて、一旦Embulkは何も加工してないデータをBigQueryに送ります。それをdbt Cloudがまとめて、さまざまな加工処理を行ってプロジェクトに移しています。」
dbt Cloud導入における振り返り

土川 稔生氏:「dbt Cloudを導入したことによって、データパイプラインからもデータを収集して共通の加工が行えるようになりました。また、dbt Cloudはインフラの整備が不要なので、チームメンバーが少ないDREチームにはすごい適切なツールで導入までのコストがすごく低かったです。
問題点として上がったのが、ETL構成をELT構成にするときに一旦加工してないデータを特定のGCPプロジェクトに保存する必要があり、GCPのIAM構成がすごい複雑でインフラの構成を修正するのがすごい大変でした。」
最終的な基盤構成

土川 稔生氏:「最終的なデータ基盤構成が図のようになっていて、trocco®やデータトランスファーサービスを使って新しいデータの繋ぎこみを少人数でできるように開発を進めております。」
これから解決していきたい課題についてお話しいただきました。
今後の課題

土川 稔生氏:「解決して行きたい課題として、適時性をSLIとして提示していましたが、他にもデータ品質をSLIは一意性・安全性などの指標があるので、それらを適用することで品質の保証をしていきたいです。
dbt CloudとLookerはどちらもBigQueryにテーブルを吐き出すことができるので、そこの使い分けを行っていきたいと考えています。dbt CloudはDREチームを中心としたデータ加工で、lookerは分析者が中心として使えるようなデータマークに近いところで加工を行っていこうと考えています。
あとは、適切な用途で適切な人が適切なBIiツールを使えるようにしっかり整えていきたいなと思っています。」
LT6「データ管理に重要なことは事業と組織の理解だった」
吉本 直人 氏
モノタロウでは今年からデータ管理を推し進めるべく、その一歩目としてDWH構築やLookerの導入を行ったものの、想定以上の時間と工数がかかってしまう結果となりました。
株式会社MonotaRO
このLTではこれらの取り組みを振り返りつつ、事業や組織の観点から学んだことをお話します。
モノタロウの行ったデータ管理

吉本 直人氏:「これまでモノタロウはBigQueryの導入やSQLの講習を通じて、エンジニアに限らずいろんな人がデータを分析・活用していく環境は進んでいます。
その一方で、同じ集計をしているつもりが違う結果といった定義管理が集約されてない問題がありました。あとはSQLが書けなくてもデータ活用できる状態にするために、データ基盤グループもよりデータ管理にフォーカスしていき、データ基盤だけでなく社内のデータに詳しい人に集まってもらってデータにフォーカスする体制を構築しました。これまでやってきた事は、「Monotaro Tech Talk」で詳細を確認してください。」
Lookerの導入とDWHを構築した結果

吉本 直人氏:「Lookerの導入とDWHの構築による恩恵はかなりありましたが、想定以上に工数かかってしまいました。例えば、データ基盤はデータの使用が分からないので、分析したいデータのロジックを知りたい時は業務側に聞いたり、逆にシステム仕様で決まったロジックで集計したい場合はどういうデータを見ればいいのかのコミュニケーションが多いです。
また、業務側から依頼されたロジックをシステム側に確認したりなど、検証を重ねて業務側の同意をとりにいくことをしています。
こういった課題が生まれる背景を考えるにあたって、自社の事業や組織を改めて見ていくことにしました。」
モノタロウの事業内容

吉本 直人氏:「モノタロウはBtoB対象とした間接資材のECサイトを展開しています。間接資材は物を作るために必要な工具を売るのが表面的な事業になっています。ただ裏側では在庫も保有しており、客さんに最適に商品を配送するための物流の最適化を行っています。また、ECにどのような商品を載せるかの商品採用や、プライベートブランドの商品開発も事業としてあります。
モノタロウは単一事業ではありますが、ドメインが結構複数にまたがっています。そして、それらのドメインのが完全に疎結合ではなく緩く繋がっているため、データのレコード少ないがテーブルの数自体が多くなります。」
売上向上に伴うシステムの刷新
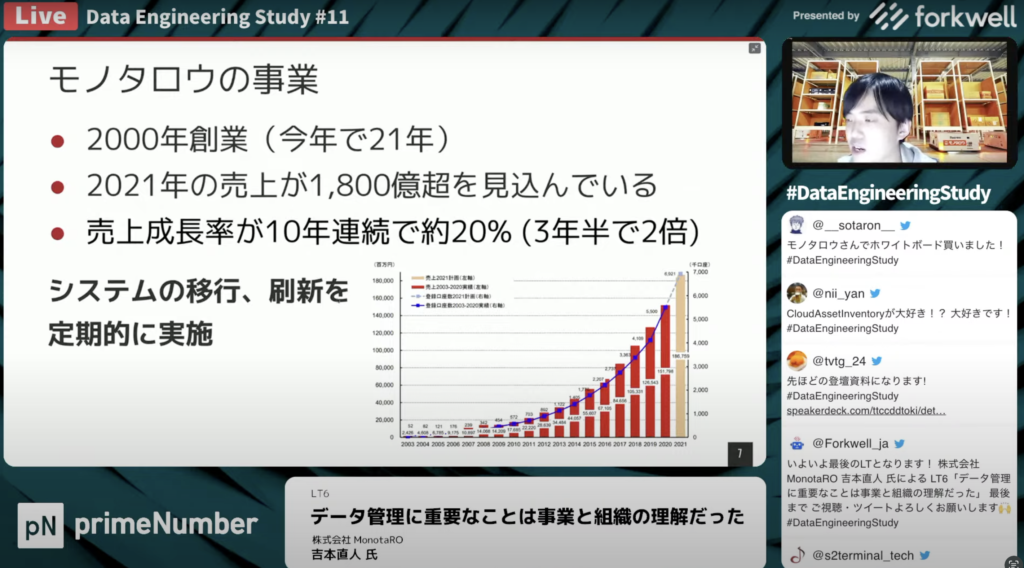
吉本 直人氏:「モノタロウは創業してから21年が経ったので、レガシーなシステムもあります。売り上げは10年連続20%成長し、注文数・顧客もそれに応じて増えています。それをさばくために倉庫を増やしたり、商品の数を増やしているため裏側のシステムが複雑になってきています。さらにそのキャパシティを支えるためにシステムの移行・刷新が各所で行われています。」
部門が多岐に渡ることでナレッジが特化しやすい

吉本 直人氏:「組織構造に関しても、ドメイン毎のシステム刷新・改善を繰り返していく中で、ドメインに沿った組織構成になりがちです。
2020年12月時点で12個の部門が存在しているため、部門ごとにナレッジが特化しやすく、ドメインに沿った組織構成になってる関係上、ドメイン間のコミュニケーションが進まないという課題がありました。」
事業と組織を理解して分かったこと

吉本 直人氏:「改めて事業や組織を理解してくると、ドメインが幅広くドメイン毎に要件が複雑になり、必要な知識がどんどん変わるためナレッジ局所化しやすいという課題がありました。
こういった現状では、事業の全体のデータの仕様を理解することは難しい考えました。しかし、ドメイン毎に分析するケースは少なく、ドメインをまたがって集計をする必要があるので、データ基盤グループだけで分析を行うのは難しいと考えました。」
今後の取り組み

吉本 直人氏:「今後はよりエンジニアの方と業務担当者を巻き込んでいくことで、データ活用のプラットフォーム作りをやっていきたいと考えています。具体的にはエンジニアの方がDWHの構築・運用に関わってもらえるような仕組みを整備することが挙げられます。
dbtなどのSQLを書くだけでDWH構築できるツールを導入したり、システム側と業務側の両ドメインにデータに詳しいオーナーを設置して、それらが相互にコミュニケーションをしながら体制を構築していく事がモノタロウのデータ基盤として取り組んでいくべき事だと考えています。」
最後に、KPTに沿ってまとめていただきました。

吉本 直人氏:「まず、今後続けていくことは今年データ管理の第一歩して、Lookerの導入とDWHの構築を実施してきましたが、問題として想定以上にリソースを使っていました。今後は他社事例を参考にしつつ、自社の事業や組織を理解した上でどのようなことをしていくべきを考える必要があると感じました。さらに、DWH構築に加えて、いろんな人が関わっていけるようなプラットフォーム作りも進めていきたいです。」
過去のData Engineering Studyのアーカイブ動画
Data Engineering Studyはデータエンジニア・データアナリストを中心としたデータに関わるすべての人に向けた勉強会を実施しております。
当日ライブ配信では、リアルタイムでいただいた質疑応答をしながらワイワイ楽しんでデータについて学んでおります。
過去のアーカイブもYoutube上にございますので、ぜひご覧ください。
https://www.youtube.com/@dataengineeringstudy6866/featured
また今回のLTでも言及あったtrocco®はフルマネージドのEmbulkサービスというだけでなく、ワークフロー機能によるジョブの実行管理、メタデータを活用したデータリネージ・データカタログ機能、OSSのdbtとのシームレスな連携を可能にするdbt連携機能などデータ分析基盤の運用をトータルでサポートするサービスです。
trocco®は、ETL/データ転送・データマート生成・ジョブ管理・データガバナンスなどのデータエンジニアリング領域をカバーした、分析基盤構築・運用の支援SaaSです。データの連携・整備・運用を効率的に進めていきたいとお考えの方や、プロダクトにご興味のある方はぜひ資料をご請求ください。
